[Lecture 1] Introduction to Convolutional Neural Networks for Visual Recognition
Opening
인터넷 세상에 있는 거의 80%의 traffic은 비디오이다. 대다수의 인터넷에 올라와 있는 자료들은 모두 비주얼 데이터이다.
따라서, 이 데이터를 이용하고 이해하는 것은 매우 중요하다. 하지만, 이는 굉장히 어렵다.
유튜브가 굉장히 좋은 통계이다. 사람들이 계속해서 만들어 내고, 구글의 직원이 이를 하나하나씩 관리할 여력이 되지 않는다.
이 때 비주얼 데이터의 내용을 이해하는 기술이 굉장히 중요할 것이다.
컴퓨터 비전은 다양한 분야들에 대한 이해를 바탕으로 이루어져야 한다. (물리학, 생물학 등)
관련된 강의 소개
CS231a : 3d reconstruction, 컴퓨터비전을 위한 센서 등
CS231n : 이미지 분류에 사용할 neural network(딥러닝)
visual recognition의 역사
현재의 컨볼루션 네트워크까지의 발전된 과정을 아는 것이 중요하다.
1) 540백만년 전 갑자기 많은 종류의 동물이 멸종하였다.
동물학자 앤드류 파커가 화석을 바탕으로, 첫 동물의 눈이 발달하였고 갑자기 볼 수 있게 되었다는 것을 발견하였다.
처음으로 볼 수 있게 되면서 삶을 사전 예방하게 되었다.
먹이는 포식자들로부터 탈출하여야 했고, 이는 진화적 군비 전쟁으로 이어졌다.
이것이 시각의 시작이었다.
특별히 지적으로 뛰어난 인간의 뇌의 뉴런은 시각 처리와 관련이 되어 있다. 이것이 가장 큰 센서리 시스템이다.
시각 시스템을 통해 움직이고, 일하고, 먹고, 등등을 한다.
따라서 시각 시스템은 지성을 가진 인간에게 중요한 역할을 한다.
인간의 기계적인 시각 시스템인 카메라는 어떨까?
2) 가장 처음의 카메라는 르네상스 시대의 Camera Obscura(1545)이다.
카메라가 진화하면서 가장 많이쓰는 센서가 되었다.
3) Gubel & Wiesel의 Electronic signal from brain(1950-1960)이다. 고양이의 뇌가 어떻게 반응하는지를 보았다.
visual processing은 뇌에서 간단한 구조로 시작되고, 뇌가 복잡하게 구조화한다는 것을 알게 되었다.
4) Block world(1963) : 첫번째 컴퓨터 비전 이론 -> visual world가 기하학적 모양으로 되어있고, 목적은 인식과 재건이었다.
the summer vision project(1966) -> visual system에 대한 연구 -> 이것으로 시작하여, 가장 중요하고 빠르게 성장하고 있음. 하지만 아직도 해결안됨
5) David marr(1970s) -> vision이 뭔지? 어떤 방향으로 computer vision이 가야하는지를 고민하였다.
인풋 이미지 -> Primal Sketch(Edges) -> 2 1/2-D sketch -> 3D model(계층적으로 3D 로 구현)

6) Generalized Cylinder(1979)
간단한 블록 세상에서 실제 물체를 인식하려면 어떻게 해야할까? 고민하였다. 하지만, 컴퓨터가 정말 느리고 데이터가 없었다.
모든 물체는 실린더 모양으로 되어있다고 가정하여 물체의 복잡도를 줄였다.
7) Pictorial Structure(1973)

Lines & Edges -> toys 정도에 그침
물체 인식이 너무 어려우면, 먼저 object segmentation을 하는게 어떨까?
8) Normalized Cut(1997)
image segmentation의 등장이었다. 픽셀 단위로 물체를 인식하는 개념.

9) Face Detection(2001)
machine learning tech -> SVM, boosting, graphical model, etc.
많은 기여를 한 것은 AdaBoosting을 realtime face-detection에서 사용한 것이었다.
컴퓨터 칩이 아직도 많이 느렸지만, 머신러닝 기법으로 리얼타임 얼굴인식을 성공하였다.

10) fuji digital camera (2006)
real-time face detector를 가진 카메라를 fuji에서 출시하였다.
11) feature-based (1999)
객체 인식을 feature-based로 해보고자 하였다. 전체 물체를 다른 동일 물체로 대입시키고자 하였다.
물체의 각도, 조명 등등 때문에 실현하기 어려운 아이디어였지만,
물체의 부분(feature)을 보자는 시각을 건네 주었다.
패턴을 맞춰보는 것보다 피쳐를 이용해서 두 개의 물체를 맞춰볼 수 있었다.

12) Spatial Pyramid Matching(2006)
이미지의 여러 부분에서 feature들을 뽑아서 feature descriptor에 넣고
support vector machine 알고리즘을 돌림

13) Histogram of Graidents(2005), Deformable Part Model(2009)
사람을 인식하고자 노력하였다.

21세기가 되면서 사진의 질이 좋아졌다
인터넷의 성장과 함께 디지털 카메라의 성능이 더더 좋아지고, 컴퓨터 비전을 수행하기에 적합하게 데이터의 질이 높아졌다.
14) PASCAL Visual Object Challence라는 데이터셋이 등장
물체 인식의 진전 정도를 측정할 수 있게 해준 벤치마크 데이터가 등장하였다.
데이터셋은 20개의 물체 클래스로 이루어져있다.

-> 2007년부터 2012년까지 예측 정확도가 꾸준히 올랐다.
문제는 너무 train set에 overfitting되었다는 것이다.
visual data는 너무 복잡하였다.
15) ImageNet : 22K 카테고리 + 14M 개의 이미지들
데이터양을 급격하게 늘려서 train set에 오버피팅 되지 않자는 목적에서 22K 카테고리 + 14M 개의 이미지를 가진 ImageNet을 만들었다.
성능을 진전시키기 위해 ImageNet Large Scale Visual Recognition Challenge을 개최하였다.

상위 5개의 클래스가 맞으면 correct로 채점한다.

2012년에 error rater가 엄청 급감 했다. -> Convolution Neural Network 등장 !!
우리 수업에서는 Convolution Neural Network 에 딥 다이브해서 알아볼 것이다.
그 중에서도 image classification에 focus 할 것이다.
object detection, image captioning(이미지를 자연어로 설명)도 할 것이다.
CNN은 물체 인식의 아주 중요한 도구가 되었다.
ImageNet Large Scale Visual Recognition Challenge 우승 모델

2010년) 아직도 계층적이다.
2012년) AlexNet. 이 때부터 모든 우승자는 Neural Network 였다. 7-8 layer를 가지고 있다.
2014년) 19 layer를 가지고 있다. (VGG)
2015년) 152개의 layer를 가진 ResNet이 개발되었다.
사실, CNN은 2012년에 나온게 아니다.
1998년에 나와서 post office에서 digit를 인식하는데 사용되었다.
1998년에 나온 모델이 2012년의 AlexNet과 비슷해 보인다.

take pixels -> classify
그렇다면 왜 2012년에 주목받게 되었을까?
1) computation (계산능력)
: 트랜지스터의 개수가 엄청나게 증가
동일한 환경에서 모델의 사이즈만 증가시켜도 성능이 증가하는 경우가 있기 때문이다.
2) data
: labeled 데이터가 많아져서, ex) PASCAL, ImageNet
많고 high-quality인 data가 수집되었기 때문이다.
더 다양하게 활용되고 있는 사례들.
Image Retrieval
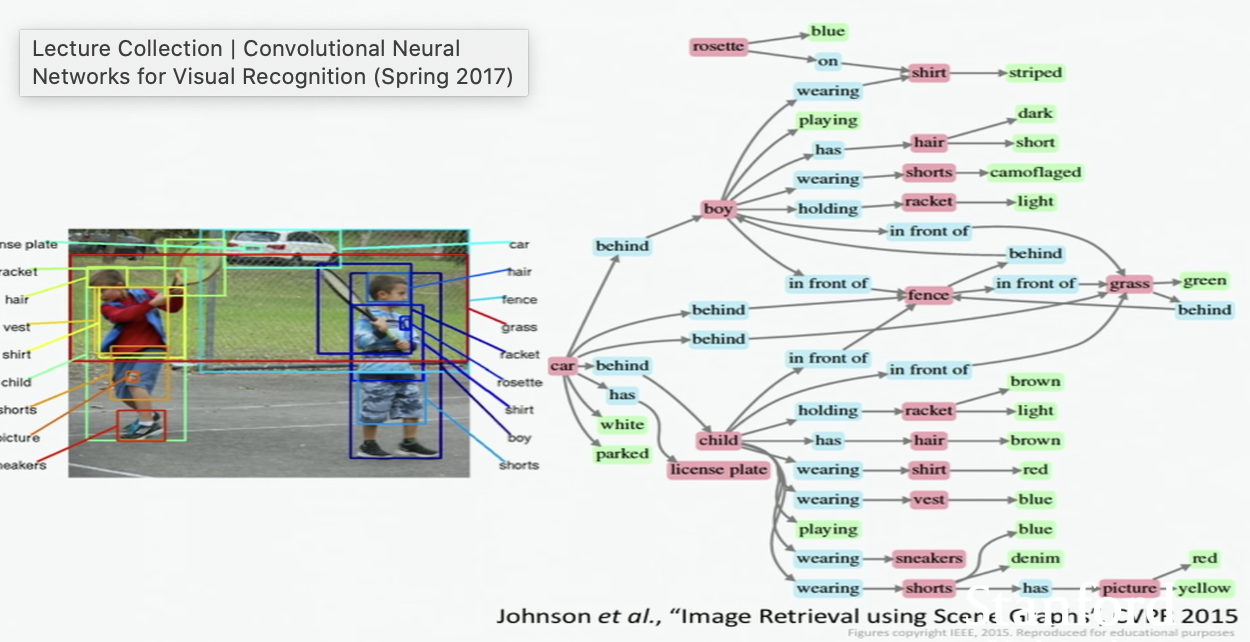
객체 뿐만 아니라 객체간의 관계와 상황, 객체의 특성을 인식할 수 있어야 한다.
Fei-Fei Lee의 연구

사람들은 잠깐의 영상을 보고 많은 양의 글로 설명할 수 있다.
수업의 철학
1) thorough and detailed : CNN 구현
2) practical
3) state of the art
4) fun
Q. 궁금한것, 더알아볼것
- support vector machine 알고리즘이 무엇인지?
- AdaBoost