[Segmentation] Segmentation Transformer: Object-Contextual Representations 논문 리뷰
논문 링크입니다.
https://paperswithcode.com/paper/object-contextual-representations-for
Papers with Code - Segmentation Transformer: Object-Contextual Representations for Semantic Segmentation
#2 best model for Semantic Segmentation on Cityscapes test (Mean IoU (class) metric)
paperswithcode.com
0. Title
Segmentation Transformer: Object-Contextual Representations for Semantic Segmentation
-> Semantic Segmentation에서 사용하는 Object-Contextual Representations 모델인가 봅니다.
Transformer 개념이 들어가는 것 같기도 하구요.
Object-Contextual Representation 이 핵심인 듯 한데, 객체-문맥 표현? 어떤거지?
1. Abstract
이 논문에서는 semantic segmentation에서 문맥 병합 문제를 다룰 것이다.
픽셀의 레이블이 픽셀이 속하는 물체의 카테고리라는 것에 착안하여,
우리는 간단하지만 효과적인 object-contextual representations라는 개념을 개발하였다.
이는, 해당 객체 클래스의 표현을 활용하여 픽셀을 characterizing 하는 것이다.
첫째로, 우리는 ground-truth segmentation을 바탕으로, 객체의 영역을 학습한다.
둘째로, 객체의 영역에 있는 픽셀들의 표현을 합침으로써 object region representation을 계산하였다.
마지막으로, 각각의 픽셀과 각각의 객체 영역 사이의 관계를 계산하고,
각각의 픽셀값을 모든 object-contextual representation을 가중치합한 object-contextual representation와 함께 증강시킨다.
우리는 경험적으로 Cityscapes, ADE20K, LIP, PASCAL-Context and COCO-Stuf에서 좋은 성능을 낸 것을 알 수 있었다.
우리는 Transformer의 encoder-decoder 프레임워크를 사용하였다.
첫번째 두개의 과정인 object region learning과 object region representation computation은
decoder의 cross-attention 모듈로서 통합되었다.
마지막 과정은 encoder에 넣는 cross-attention module이다. 키와 value가 decoder의 output이고,
쿼리들은 각각의 위치에서의 표현이다.
1. Conclusions
우리는 semantic segmentation에서의 object-contextual representation approach를 제안한다.
성공의 가장 큰 이유는 픽셀의 레이블이 해당 픽셀이 속한 객체의 레이블이기 때문이다.
그리고 각각의 픽셀을 객체 영역 표현과 함께 characterizing함으로써 픽셀 표현이 강화되었기 때문이다.
즉, 픽셀을 그 픽셀이 포함된 객체 정보와 연결시킴으로써 예측 정확도가 높아졌다는 것이다.
우리는 경험적으로 Cityscapes, ADE20K, LIP, PASCAL-Context and COCO-Stuf에서 좋은 성능을 낸 것을 알 수 있었다.
2. Introduction
Semantic segmentation은 이미지에서 각각의 픽셀에 클래스 레이블을 할당하는 문제이다.
이것은 computer vision에서 근본적인 문제이며 자율주행과 같은 다양한 실용적인 태스크에 핵심적이다.
DCNN은 FCN부터 시작해서 지배적인 해결방법이었다.
HRNet, contextual aggregation을 포함하여 다양한 연구가 수행되어왔고 이것이 곧 이 논문의 관심 주제이다.
한 위치의 문맥은 일반적으로 주위의 픽셀들을 포함한 여러 세트의 위치를 나타낸다.
이전의 연구들은 주로 문맥의 공간적 스케일에 관하여 수행되었다.(spatial scope과 같은)
ASPP와 PPM과 같은 representation work는 multi-scale 문맥을 활용하였다.
DANet, CFNet, OCNet과 같은 최근의 연구는
위치와 그 위치의 문맥적 위치의 관계를 고려하고, 동일한 표현의 상위 weight와 문맥적 위치의 표현을 통합하였다.
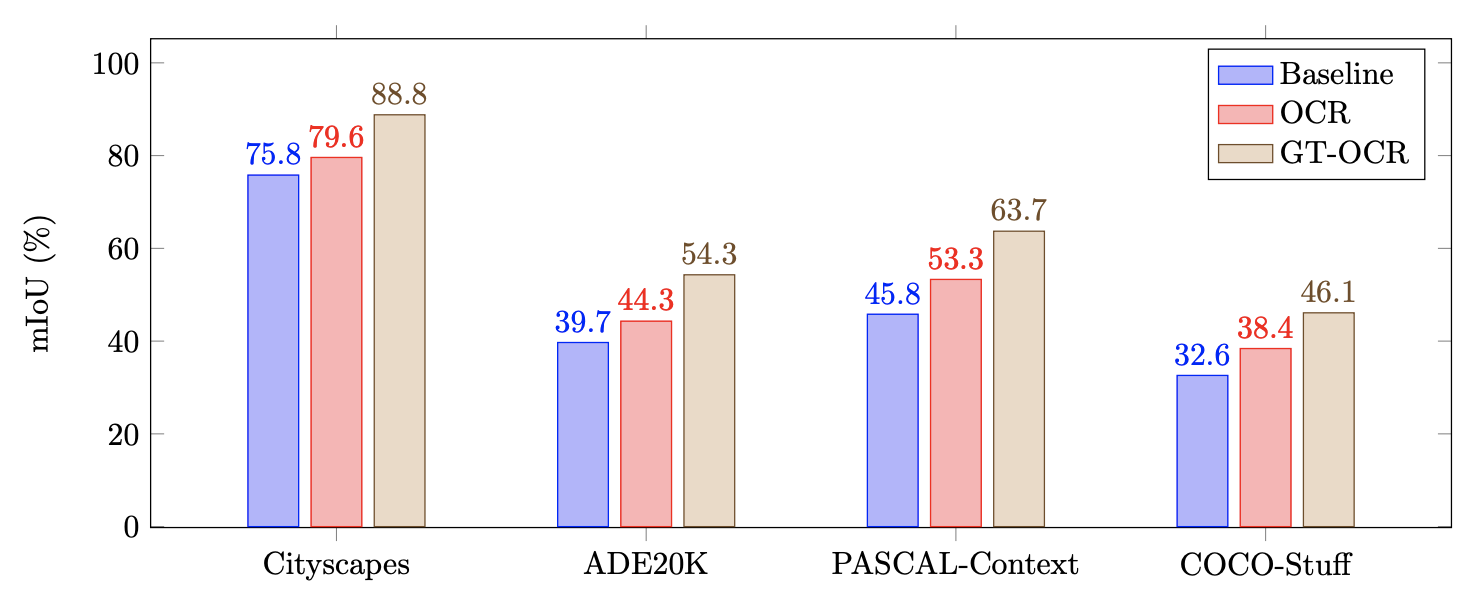
GT-OCR은 ground-truth를 이용함으로써 이상적인 OCR을 예측하였다.
우리는 position과 그것의 context 사이의 관계를 탐색하는 라인을 따라서
contextual representation을 조사하기로 하였다.
픽셀에 할당된 클래스 레이블은 해당 픽셀이 포함된 객체의 카테고리라는 것이 핵심 아이디어였다.
대응되는 클래스의 객체 영역의 표현을 이용함으로써 한 픽셀의 표현을 증강시키는 것을 목표로 한다.
Fig 1.을 통해 알 수 있듯, ground-truth object region이 주어질 때,
그러한 representation augmentation scheme이 segmentation quality를 높여준다.
우리의 접근법은 세 가지 단계로 이루어져 있다.
첫째, 우리는 contextual pixel 을 soft object region으로 분할할 수 있다. (ResNet, HRNet과 같은 딥 네트워크로부터 계산된 거칠고 소프트한 세그먼테이션)
- 이러한 분할은 GT segmenation의 감독 아래 학습된다. (즉, GT를 이용한다.)
둘째, 대응되는 object region에서 픽셀의 표현을 병합함으로써 각각의 object region의 표현을 추정한다.
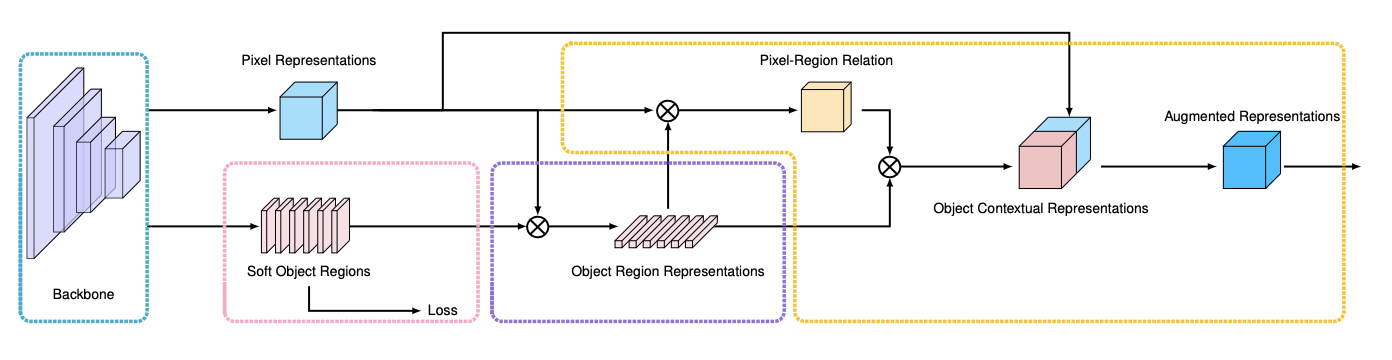
셋째, 각각의 픽셀 표현을 OCR과 함께 증강시킨다.
- OCR은 모든 object region representation의 가중치 합이다.
- weight는 픽셀과 object region 사이의 관계를 따라 계산된다.
OCR은 기존의 multi-scale context scheme과는 차이가 있다.
우리의 OCR은 다른 객체 클래스의 contextual pixel과 동일 객체 클래스의 contextual pixel을 구별합니다.
반면, ASPP나 PPM과 같은 multi-scale context scheme에서는 공간적 위치의 차이만 구별한다.

게다가, 우리는 contextual 픽셀을 object region으로 구조화하고, 픽셀과 object 사이의 관계를 이용한다.
반면, 이전의 relational context schemes들은 contextual 픽셀을 분리하여 고려하였고,
픽셀과 contextual 픽셀 간의 관계만을 이용하거나 region에 대한 고려 없이 픽셀로부터의 관계를 예측하였다.
우리의 모델은 다양한 semantic segmentation 챌린지에서
multi-scale context schemes(PSPNet, DeepLabv3)와 relational context schemes(DANet)의 성능을 능가하였고
메모리 상에서도 더 효율적이었다.
또한, 우리의 접근법을 Panoptic-FPN으로 확장시켰고 COCO panoptic segmentation task에서 그 성능을 입증하였다.
3. Approach
1) Background
더 알아볼 것
- ASPP
- Transformer
- representation의 뜻?