
W는 Input의 해당 픽셀이 얼마나 특정 클래스에 영향을 미치는 지에 대한 값이다.
W의 사이즈 = (클래스 개수) x (인풋 이미지의 픽셀 개수)
W를 계산해낸 이 loss function은 score 를 보고 W가 얼마나 양적으로 나쁜지 알려주는 척도이다.
이 강의에서 여러가지 loss function을 소개할 것이다.
가장 적게 나쁜 W를 찾아가는 과정이 "최적화" 과정이다.
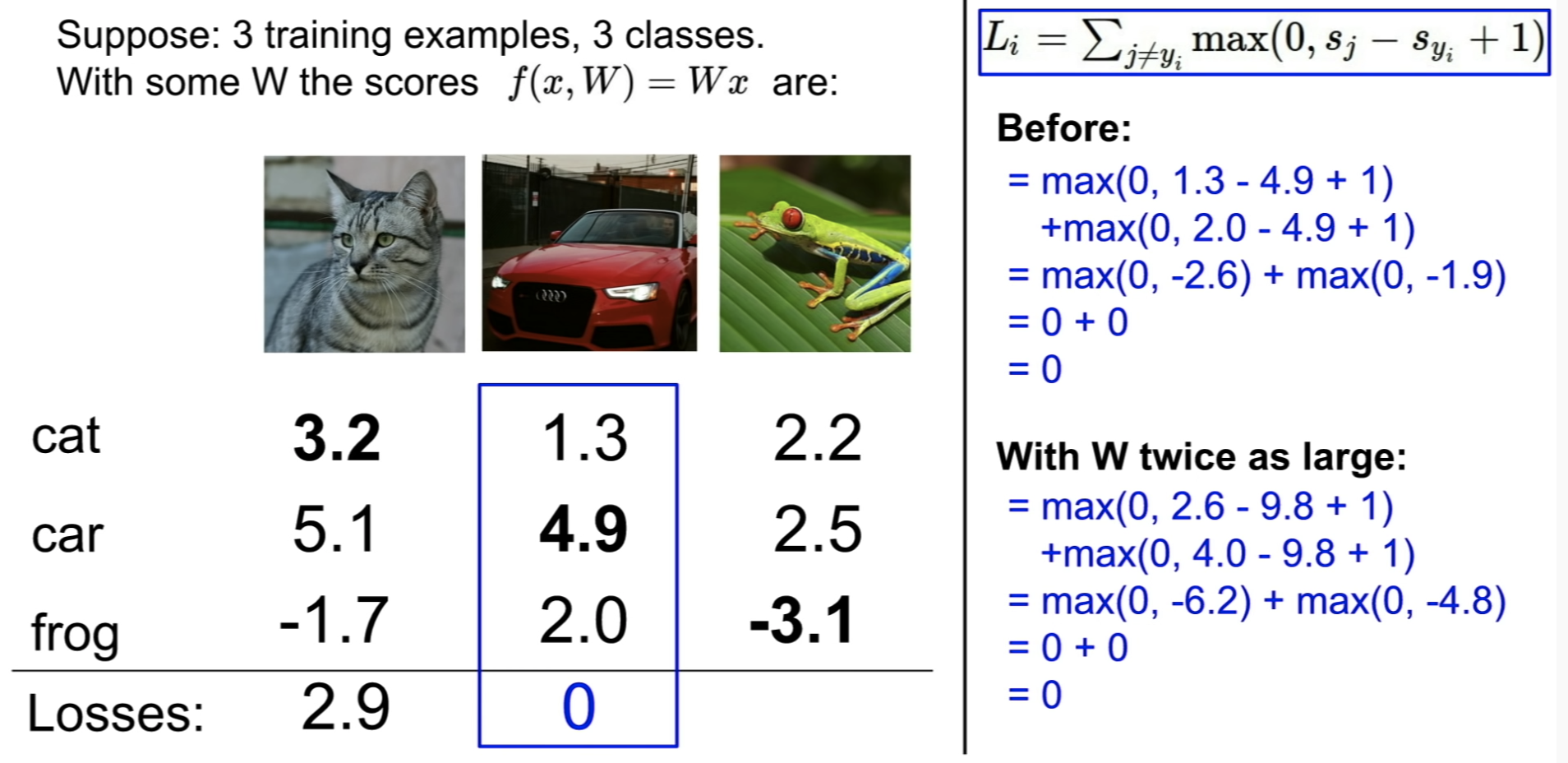
Loss function : multi-label SVM
image classification 에서 많이 쓰는 것 -> multi-label SVM

만약 맞는 클래스의 score가 틀린 클래스의 score보다 월등히 크다면, Loss는 0으로 설정한다.
그렇지 않다면, 맞는 클래스의 score에서 틀린 클래스의 score을 빼는 방식으로 Loss를 계산한다.
Hinge Loss 라고도 부른다. x축은 맞는 클래스의 score이고, y축은 loss이다.
맞는 클래스 score이 높아지면, loss는 감소한다.
loss가 0이 되면 잘 분류한 것으로 보면 된다.
from builtins import range
import numpy as np
from random import shuffle
from past.builtins import xrange
def svm_loss_naive(W, X, y, reg):
"""
Structured SVM loss function, naive implementation (with loops).
Inputs have dimension D, there are C classes, and we operate on minibatches
of N examples.
Inputs:
- W: A numpy array of shape (D, C) containing weights.
- X: A numpy array of shape (N, D) containing a minibatch of data.
- y: A numpy array of shape (N,) containing training labels; y[i] = c means
that X[i] has label c, where 0 <= c < C.
- reg: (float) regularization strength
Returns a tuple of:
- loss as single float
- gradient with respect to weights W; an array of same shape as W
"""
dW = np.zeros(W.shape) # initialize the gradient as zero
# compute the loss and the gradient
num_classes = W.shape[1]
num_train = X.shape[0]
loss = 0.0
for i in xrange(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]]
loss_contributors_count = 0
for j in xrange(num_classes):
if j == y[i]:
continue
margin = scores[j] - correct_class_score + 1
if margin > 0:
loss += margin
dW[:, j] += X[i] # [GD] 틀린 애
loss_contributors_count += 1
dW[:, y[i]] += (-1) * loss_contributors_count * X[i] # [GD] 맞는 애
loss /= num_train
dW /= num_train
# [Regularization]
loss += reg * np.sum(W * W)
dW += 2 * reg * W
#############################################################################
# TODO: #
# Compute the gradient of the loss function and store it dW. #
# Rather that first computing the loss and then computing the derivative, #
# it may be simpler to compute the derivative at the same time that the #
# loss is being computed. As a result you may need to modify some of the #
# code above to compute the gradient. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW
def svm_loss_vectorized(W, X, y, reg):
"""
Structured SVM loss function, vectorized implementation.
Inputs and outputs are the same as svm_loss_naive.
"""
loss = 0.0
dW = np.zeros(W.shape) # initialize the gradient as zero
#############################################################################
# TODO: #
# Implement a vectorized version of the structured SVM loss, storing the #
# result in loss. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
num_train = X.shape[0]
s = X.dot(W)
correct_score = s[list(range(num_train)), y]
correct_score = correct_score.reshape(num_train, -1)
s += 1 - correct_score
s[list(range(num_train)), y] = 0
loss = np.sum(np.fmax(s, 0)) / num_train
loss += reg * np.sum(W * W)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#############################################################################
# TODO: #
# Implement a vectorized version of the gradient for the structured SVM #
# loss, storing the result in dW. #
# #
# Hint: Instead of computing the gradient from scratch, it may be easier #
# to reuse some of the intermediate values that you used to compute the #
# loss. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
X_mask = np.zeros(s.shape)
X_mask[s > 0] = 1
X_mask[np.arange(num_train), y] = -np.sum(X_mask, axis=1)
dW = X.T.dot(X_mask)
dW /= num_train
dW += 2 * reg * W
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW
ex)


Q. 어떻게 +1을 정한거죠?
score의 절대적인 값이 아니라 score들 간의 상대적인 차이가 의미가 있는 것이고,
correct score이 incorrect score보다 상당히 높아야 하기 때문에 +1을 한 것이다.
1이라는 숫자는 미분 계산을 통해 씻겨 나가기 때문에 영향이 거의 없어서 괜찮다.
loss값은 상대적인 값임.
Q. 만약 car의 score가 조금 바뀐다면, loss 값도 변할까?
A. No, 이미 다른 틀린 score보다 1이상 크기 때문에 score가 조금 바뀌어도 loss에는 영향이 없다.
Q. multiclass SVM loss의 최소, 최대값은?
A. 최소 : 0, 최대 : 무한대
Q. correct score과 incorrect score의 차이가 거의 없다면 multiclass SVM loss는 어떻게 될까?
A. (class의 개수) - 1
=> 좋은 디버깅 툴임.
Q. multiclass SVM loss에서 max를 mean으로 변경하면?
A. 차이가 없다. loss값의 상대적인 차이가 의미가 있는 것이므로 max든 mean으로 하든간에 차이가 없다.
Q.multiclass SVM loss에서 제곱을 추가한다면?
A. 차이가 있다. 차이가 큰 값의 차이를 더 키우는 것이기 때문에 다른 의미가 된다.
Q. L = 0으로 만드는 W가 있다면, 이 값 하나 뿐일까?
A. 아니다.
Loss function은 어떤 타입의 에러를 더 고려하느냐를 결정하는 것.

loss가 0인 W가 두배가 된다고 하더라도 loss는 still 0
모델과 loss function은 training이아니라 test dataset에서 잘 작동해야한다.
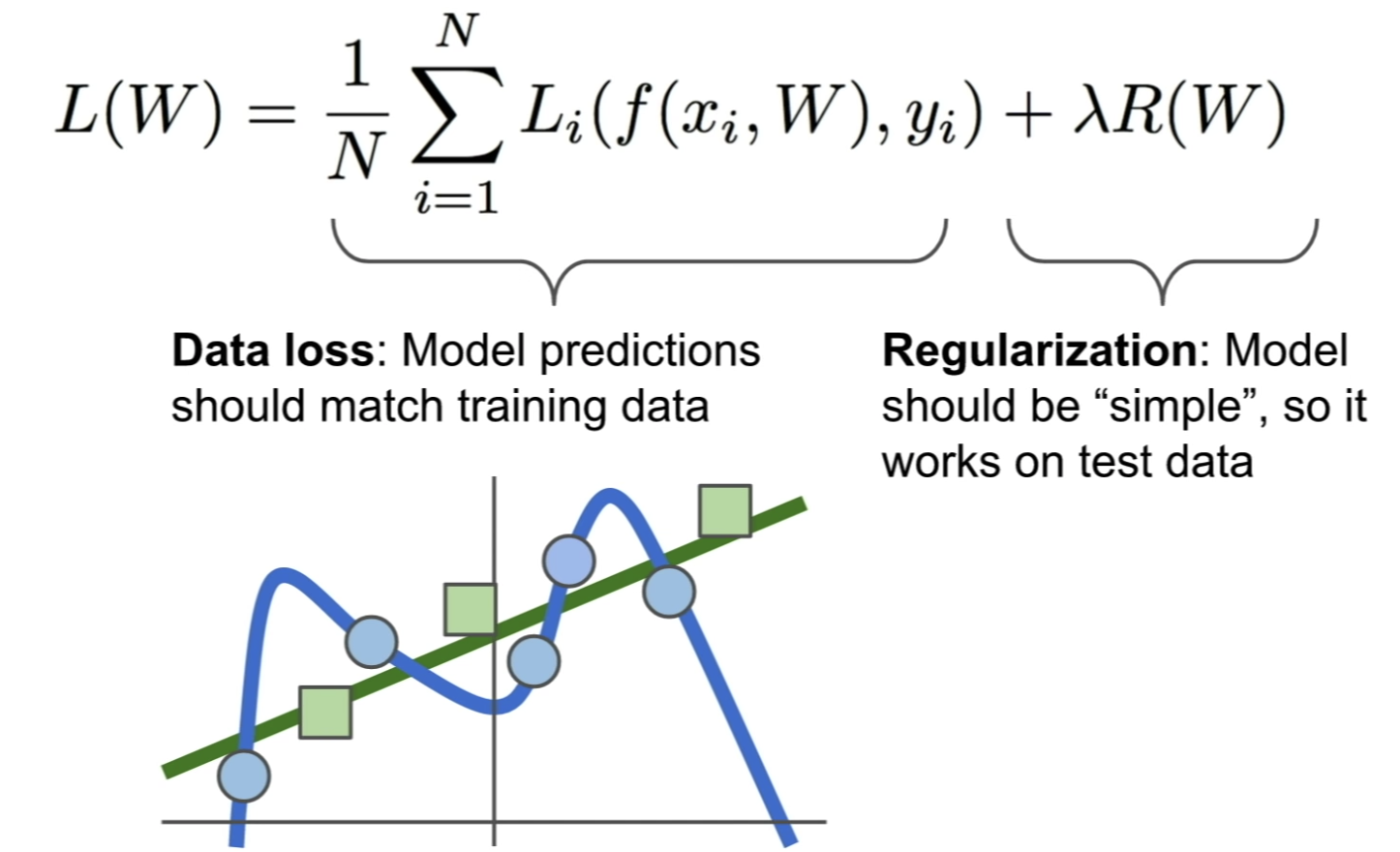
training set에만 너무 fit하지 않고 제너럴한 모델을 만들기 위해서
우리는 regularization이라는 방법을 사용한다.
람다는 하이퍼파라미터인데, 굉장히 중요한 요소이다.
Regularization


L2 regularization은 w2를 선호할 것이다. norm 이 더 작기 때문에. L2는 값이 골고루 spread 되어 있는 것이 덜 복잡하다고 판단한다.
L1 regularization은 w1를 선호할 것이다. 값은 같지만, L1은 직관적으로 sparse solution(대부분이 0이고 소수만 non-zero인)을 선호하기 때문이다. L1의 complexity 측정 방식은 non-zero값의 개수일 것이다.
L2 Loss 는 직관적으로 오차의 제곱을 더하기 때문에 Outlier 에 더 큰 영향을 받는다.
L1 Loss 가 L2 Loss 에 비해 Outlier 에 대하여 더 Robust(덜 민감 혹은 둔감) 하다.
L2 Loss 는 모든 데이터에서 score가 고르게 분포할 것을 유도.
모델과 태스크에 따라 L1, L2 정규화 방식을 선택할 것!
Softmax Classifier(Multinomial Logistic Regression)
SVM에서는 점수에 어떠한 해석을 하지 못했다.
하지만 softmax classifier에서는 점수에 대한 해석을 할 수 있다.
softmax는 0~1의 확률 분포를 뱉어낸다.
정답 확률을 모든 확률의 합으로 나눈 것에 -Log를 취한다. (KL divergence)
만약, 정답 확률이 높아서 거의 1에 가깝다면, loss는 정답 확률에 negative log를 취한 것이 될 것이다.
즉, 정답 확률이 높을수록 loss는 감소한다.


def softmax_loss_naive(W, X, y, reg):
"""
Softmax loss function, naive implementation (with loops)
Inputs have dimension D, there are C classes, and we operate on minibatches
of N examples.
Inputs:
- W: A numpy array of shape (D, C) containing weights.
- X: A numpy array of shape (N, D) containing a minibatch of data.
- y: A numpy array of shape (N,) containing training labels; y[i] = c means
that X[i] has label c, where 0 <= c < C.
- reg: (float) regularization strength
Returns a tuple of:
- loss as single float
- gradient with respect to weights W; an array of same shape as W
"""
# Initialize the loss and gradient to zero.
loss = 0.0
dW = np.zeros_like(W)
#############################################################################
# TODO: Compute the softmax loss and its gradient using explicit loops. #
# Store the loss in loss and the gradient in dW. If you are not careful #
# here, it is easy to run into numeric instability. Don't forget the #
# regularization! #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
num_classes = W.shape[1]
num_train = X.shape[0]
for i in xrange(num_train):
scores = X[i].dot(W)
scores -= scores.max()
scores_expsum = np.sum(np.exp(scores))
cor_ex = np.exp(scores[y[i]])
loss += - np.log( cor_ex / scores_expsum)
dW[:, y[i]] += (-1) * (scores_expsum - cor_ex) / scores_expsum * X[i] # [gd] 맞은 애
for j in xrange(num_classes):
if j == y[i]:
continue
dW[:, j] += np.exp(scores[j]) / scores_expsum * X[i] # [gd] 틀린 애
loss /= num_train
dW /= num_train
# [regulation]
loss += reg * np.sum(W * W)
dW += 2 * reg * W
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW
Q. softmax의 최소, 최대값은?
A. 최소값 : 0, 최대값 : 무한대(정답 확률이 마이너스 무한대일 때)
Q. 모든 s가 거의 0에 가까울 때 loss는?
A. -log(1/C) = logC
=> senity check? => 좋은 디버깅 툴임.
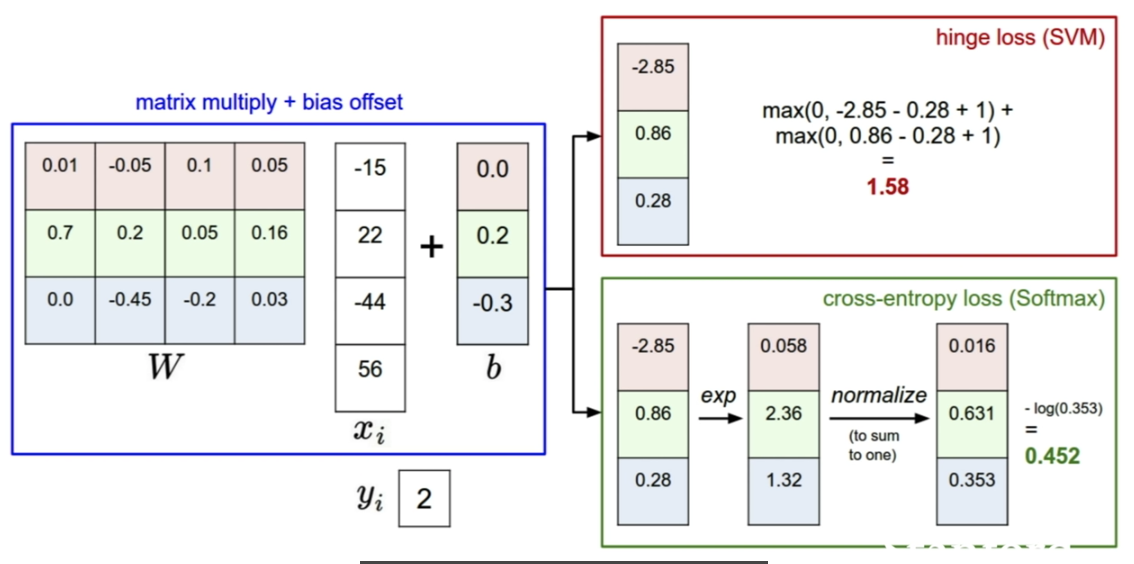
correct label의 score과 incorrect label의 score의 값이 매우 차이가 나면,
SVM은 correct score가 조금 바뀌어도 loss 값에 영향이 없지만,
softmax loss값은 바뀐다.
loss function은 GT보다 얼마나 다른지 알려주는 지표가 된다.
loss를 최소화하는 W를 선택한다. -> 딥러닝 학습 과정

어떻게 W를 변경하며 최적 값을 찾을까?
optimization function
optimization function #1 random search
bad idea
optimization function #2 follow the slope
work well
slope -> derivative of a function 미분값
gradient -> the vector of partial derivative along each dimension
h만큼의 어떤 방향으로든 이동한다고 가정하면 기울기를 반환한다.
[ numeric gradient ]
모든 W값의 값의 미분값을 구한다. -> 매우 시간이 많이 걸림.

하지만, 다행히도 이 과정을 할 필요가 없다.
loss가 그 자체로 W의 함수이기 때문에, loss function에 w로 편미분을 하면 된다.
[ analytic gradient ]


Gradient Descent
W를 랜덤으로 초기화하고
weight를 계속 gradient의 반대 방향으로 업데이트한다.
gradient는 높은 지점을 향해서 가기 때문에, 반대 방향으로 마이너스를 붙여서 업데이트 한다.
step size = learning rate => 하이퍼 파라미터

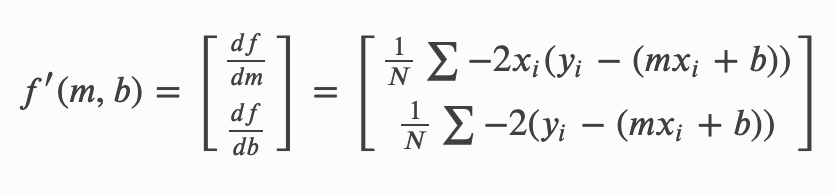
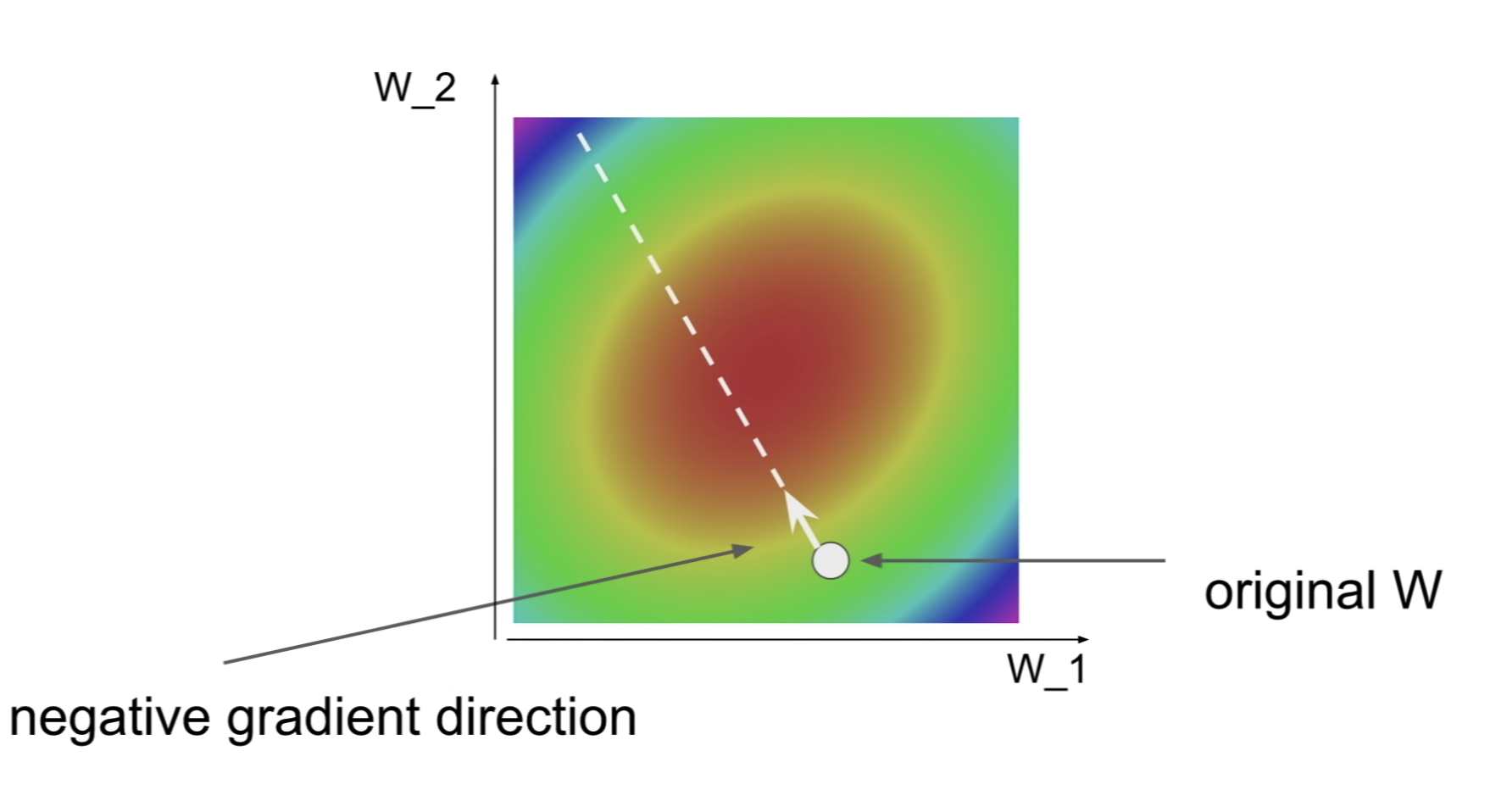
SGD
샘플된 미니배치를 사용함으로써 계산 속도를 빠르게 하는 방법.

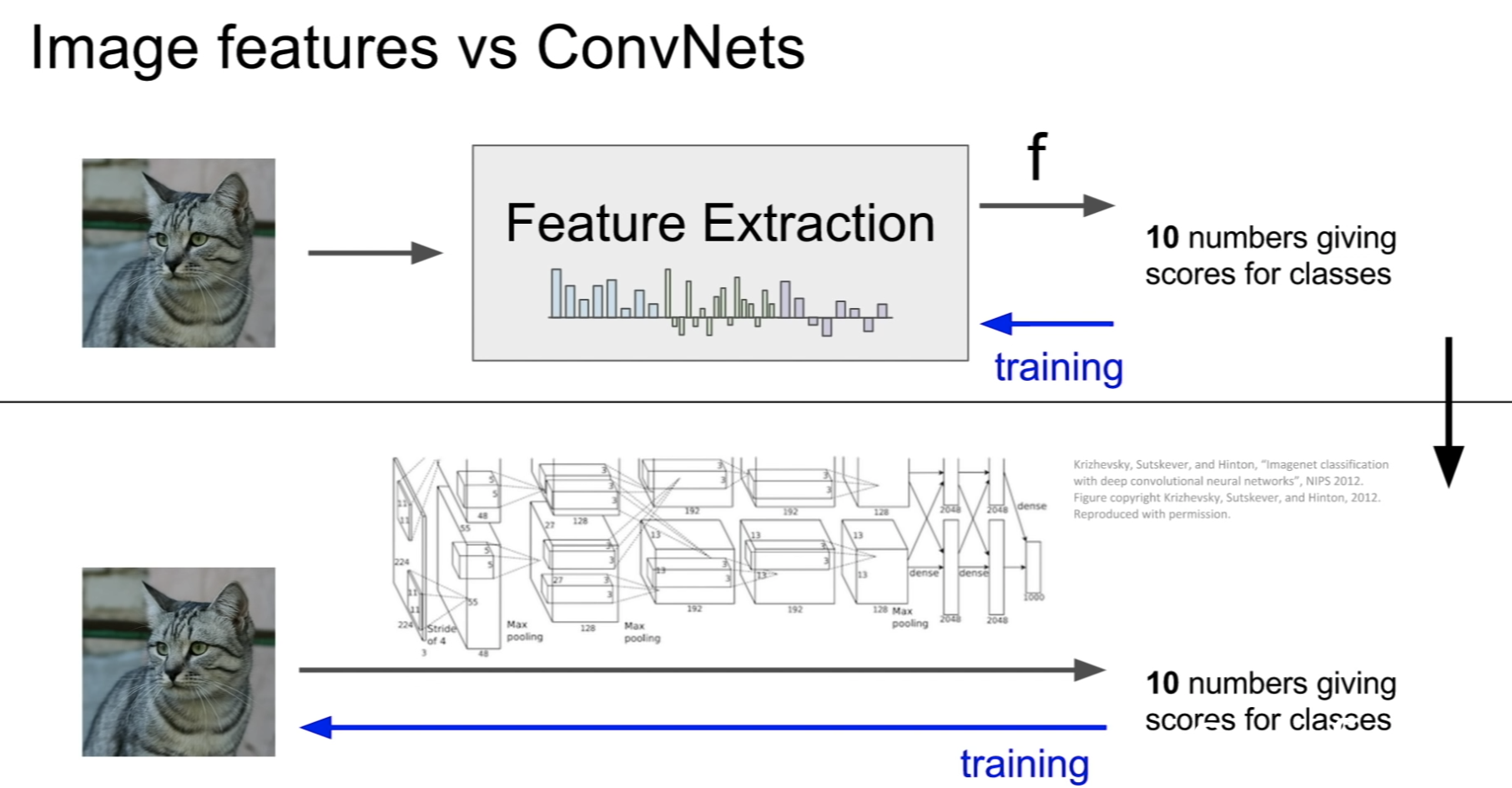
Image Features representation 여러 방식
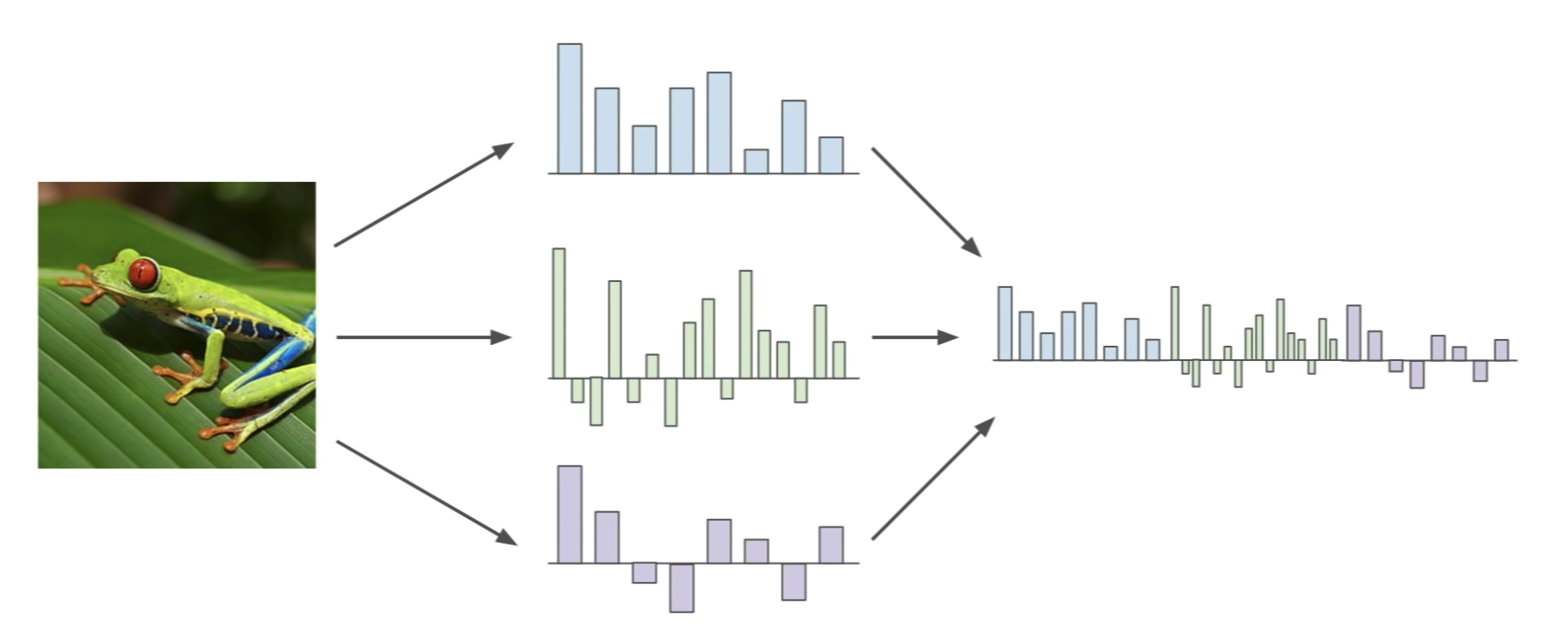
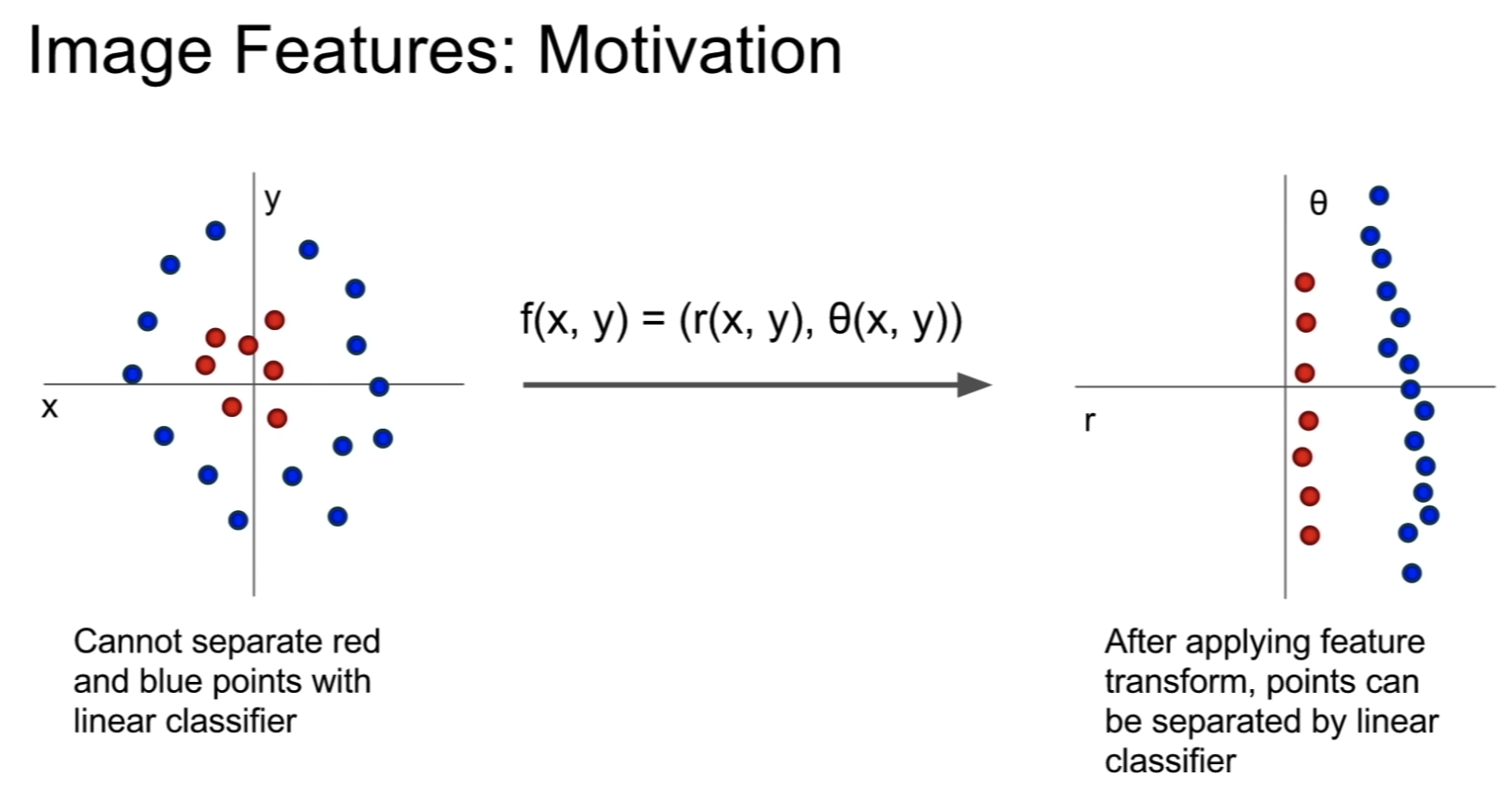

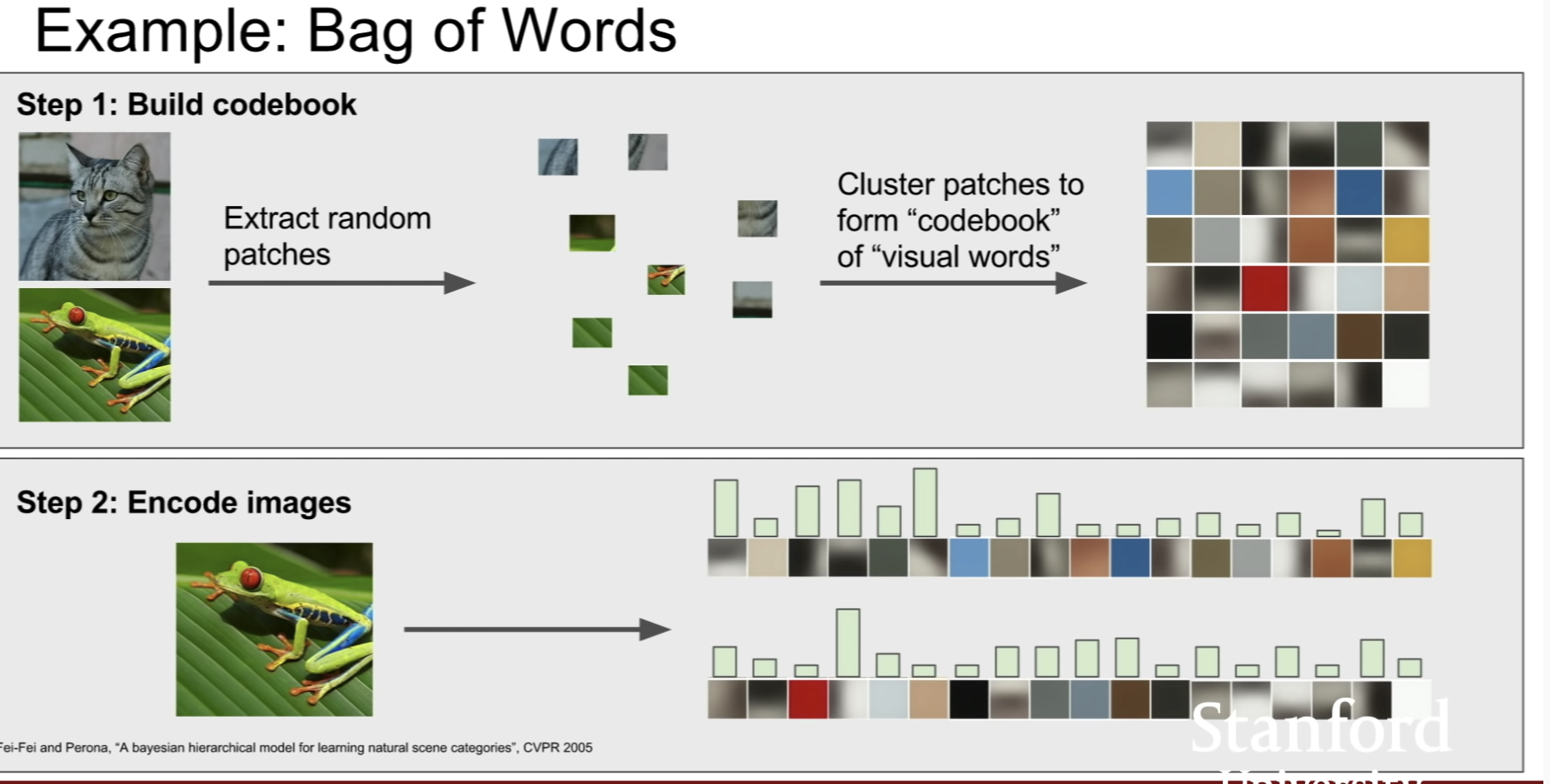
Image features vs ConvNets
Q. 궁금한 점 \ 알아볼 점
- penalizing이 무슨 뜻인지?
오버피팅을 막고 일반화한다는 것인가? 아니면 학습한다는 것인가?
- numeric gradient -> analytic gradient?
- 과제에서 dw는 어떻게 구하는 건지??
'AI > CS231n' 카테고리의 다른 글
| [Lecture 6] Training Neural Networks I (0) | 2022.05.18 |
|---|---|
| [Lecture 5] Convolutional Neural Networks (0) | 2022.05.17 |
| [Lecture 4] Introduction to Neural Networks (0) | 2022.05.17 |
| [Lecture 2] Image Classification (0) | 2022.05.12 |
| [Lecture 1] Introduction to Convolutional Neural Networks for Visual Recognition (0) | 2022.05.11 |