질문을 SQL문으로 변환

# 단어의 뜻을 어떻게 표현할까?
- 단어, 문맥으로부터 표현
- 사람이 표현하려는 방향으로
- 예술과 글쓰기의 방식으로
# 컴퓨터에서는 어떻게 단어를 해석할까?
- 일반적인 NLP 솔루션 : WordNet
Wordnet은 동의어 세트로 구성되어 있음
- Wordnet의 문제
: 뉘앙스가 생략됨
: 새로운 뜻을 놓침 -> 새롭게 정의된
: 단어간의 유사성을 측정하기 힘듦
# 전통적인 머신러닝 기반 NLP : discrete symbols
에서는 각각의 단어를 분리적으로 생각하고 본다.
one-hot vector로 보기 때문에 단어 간 유사성을 계산할 방법이 없다.
# Context
하나의 단어가 주어질 때, 항상 context(즉, 문맥)을 고려해야 한다.
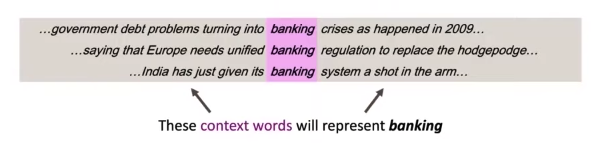
단어를 벡터로 표현할 수 있다. 비슷한 벡터는 비슷한 문맥을 가진다고 볼 수 있다.


# Word2vec 알고리즘
- 우리는 text의 corpus(신체)를 가지고 있다
- 모든 단어는 벡터로 표현될 수 있다
- 각각의 위치 t는 center word(c)와 context(o)를 가지고 있다.
- c(center)가 있는 하에서(조건부) o(outside)의 확률을 계산하기 위해 단어 벡터들 간의 유사성를 사용한다.
- 이 확률을 높이기 위해 단어 벡터를 계속해서 조정한다.

# 확률 계산법 : obejctive function
likelihood 는 각각의 포지션 t에 대해서, 각각의 center word에 대해서 확률을 구한다.
objective function은 likelihood에 평균 negative log를 취한 것으로,
목적 함수가 적을 수록(= 예측 정확도가 높을수록) 좋다.

# prediction function
1) o와 c의 유사도를 비교하기 위해 Dot product를 한다. (높은 dot product = 높은 확률)
3) 확률 분포를 구하기 위해 전체 단어로 normalize한다.

* softmax 함수는 모든 값을 0에서 1 안에 들어오게 한다.
즉, 임의의 xi 값을 확률 분포인 pi로 매핑해준다.
- max : 가장 큰 값을 증폭시키기 때문에
- soft : 작은 값들에게도 확률값을 할당하기 때문에

# model을 학습하기 : loss를 최소화하기 위해 파라미터를 최적화
d : 몇차원인지, : 단어의 개수, V 2 : center vector와 contect vector

# 수식





결론

# 코드로 보기




man : king = woman : queen
# 궁금한 점
- corpus란?
- 각 단어들의 벡터는 어떻게 구하는지?
'AI > CS224n' 카테고리의 다른 글
| Lecture 4 - Syntactic Structure and Dependency Parsing (0) | 2022.08.03 |
|---|---|
| Lecture 3 - Backprop and Neural Networks (0) | 2022.07.27 |
| Lecture 2 - Neural Classifiers (0) | 2022.07.19 |