1. B+ tree 인덱스
: 관계형 데이터베이스에서 가장 널리 사용되는 인덱스 구조이다.

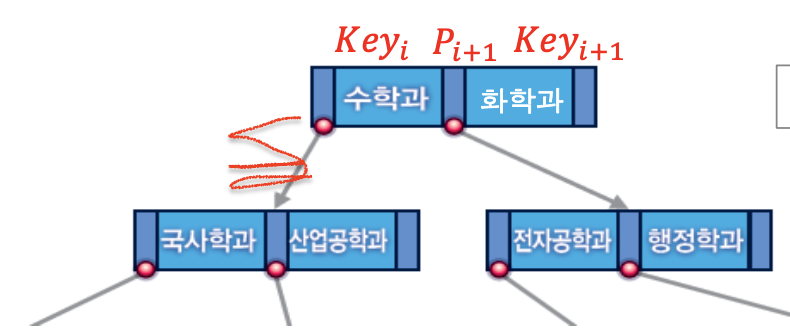
1) 차수가 n인 B+tree
차수 : 한 노드에서 하위 자식 노드를 가리키는 주소의 개수이다.
중간 노드 구조

P1 ~ Pn : 자식 노드를 가리키는 포인터
Key1 ~ Keyn-1 : 검색 키
Pi+1이 가리키는 하위 노드의 모든 검색 키는 Keyi 보다 크고 Keyi+1보다 작거나 같다.
2) B+tree 의 특징(차수가 n이라고 가정)
: 단말 노드에 레코드의 주소를 저장한다.
- 레코드의 검색 키 값에 따라 인덱스 엔트리들이 정렬된 형태이다.
- 단말 노드들이 검색 키 순서에 따라 연결된다.(다음 노드의 주소를 포함)
: 루트 노드에서 단말 노드까지의 모든 경로의 길이가 같다. (balanced tree)
: 루트 노드는 최소 2개, 최대 n개의 자식 노드를 가진다.
: 루트와 단말 노드를 제외한 중간 노드들은 최소 [n/2] (올림기호), 최대 n개의 자식 노드를 가진다.
K개의 검색 키 값을 포함하는 B+tree의 높이 = [lognK]
3) B+tree 의 성능
: 차수가 10이고 검색 키의 값이 10,000개 이면 B+tree의 높이는 4를 넘지 않는다.

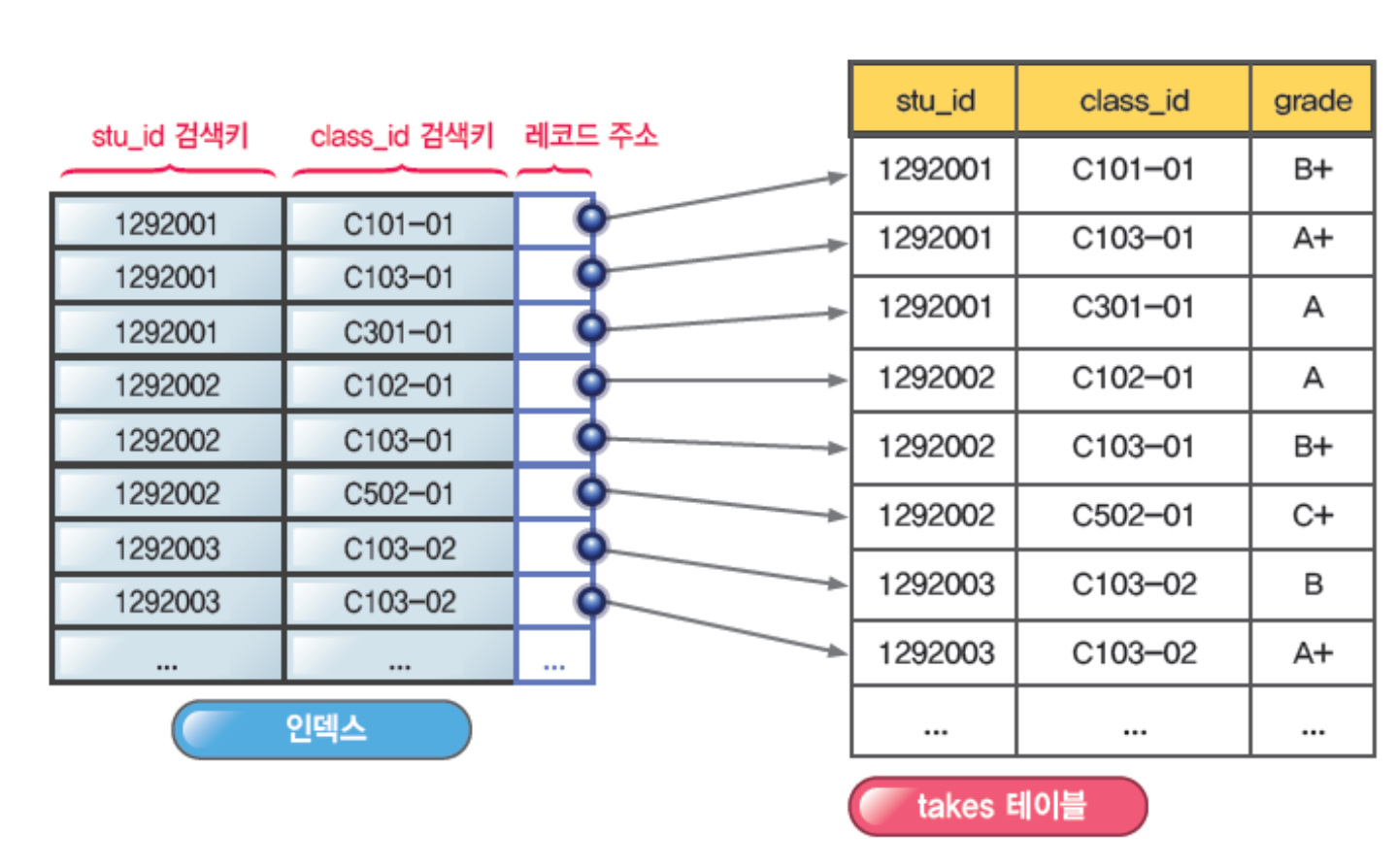
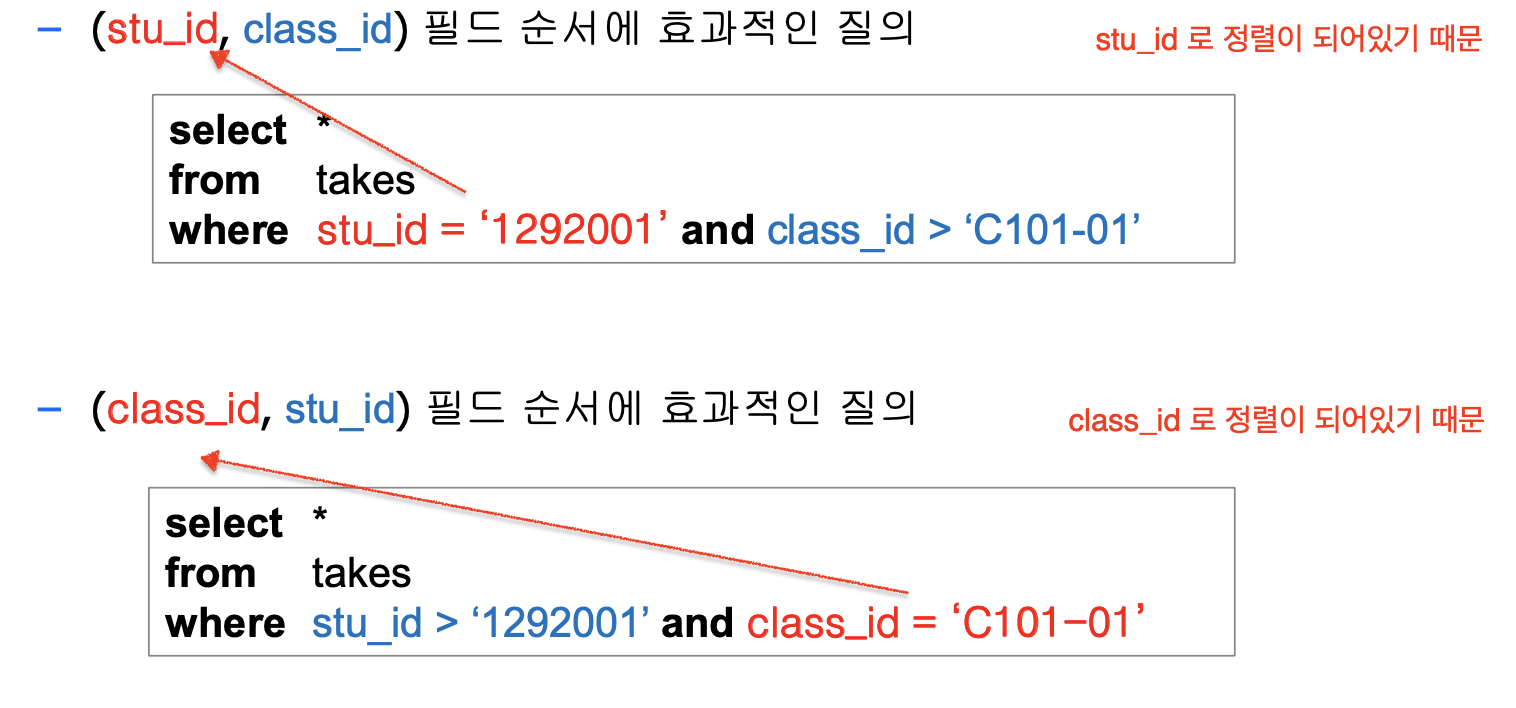
2. 복합 인덱스
: 두 개 이상의 필드에 대해 정의되는 인덱스이다.

- 인덱스 엔트리들은 검색키의 값은 순서대로 정렬된다.
- 효율적인 검색을 위해 B+ tree 구성이 가능하다.
1) 복합 인덱스 정렬 방법
: 검색 키 값이 숫자인 경우 크기로 정렬 가능하다.
: 문자열인 경우 사전식 순서에 따라 정렬한다.
: 문자열 / 숫자가 아닌 경우, 엔트리들 간에 대소 관계 정의가 필요하다.

2) 복합 인덱스의 효과
: 복합키 필드들에 대한 동등 조건을 포함하는 질의 처리 성능을 향상시킨다.
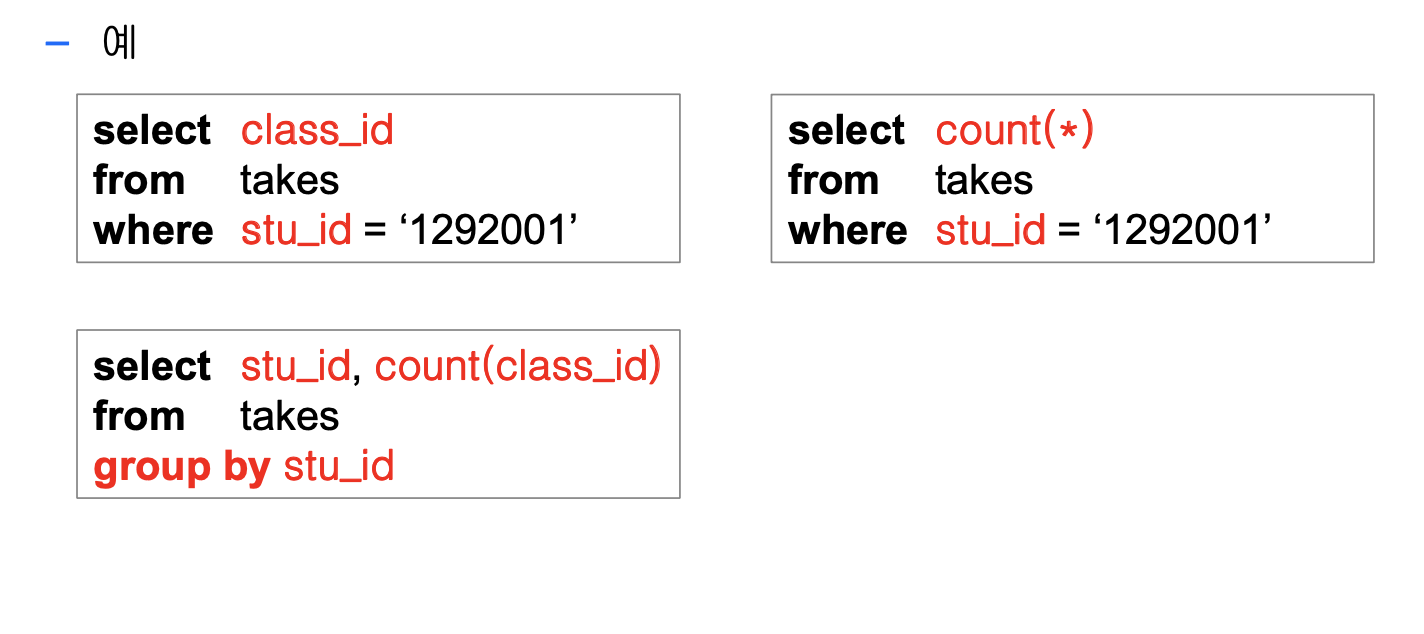
SELECT *
FROM TAKES
WHERE STU_ID = '1292001' AND CLASS_ID = 'C101-01';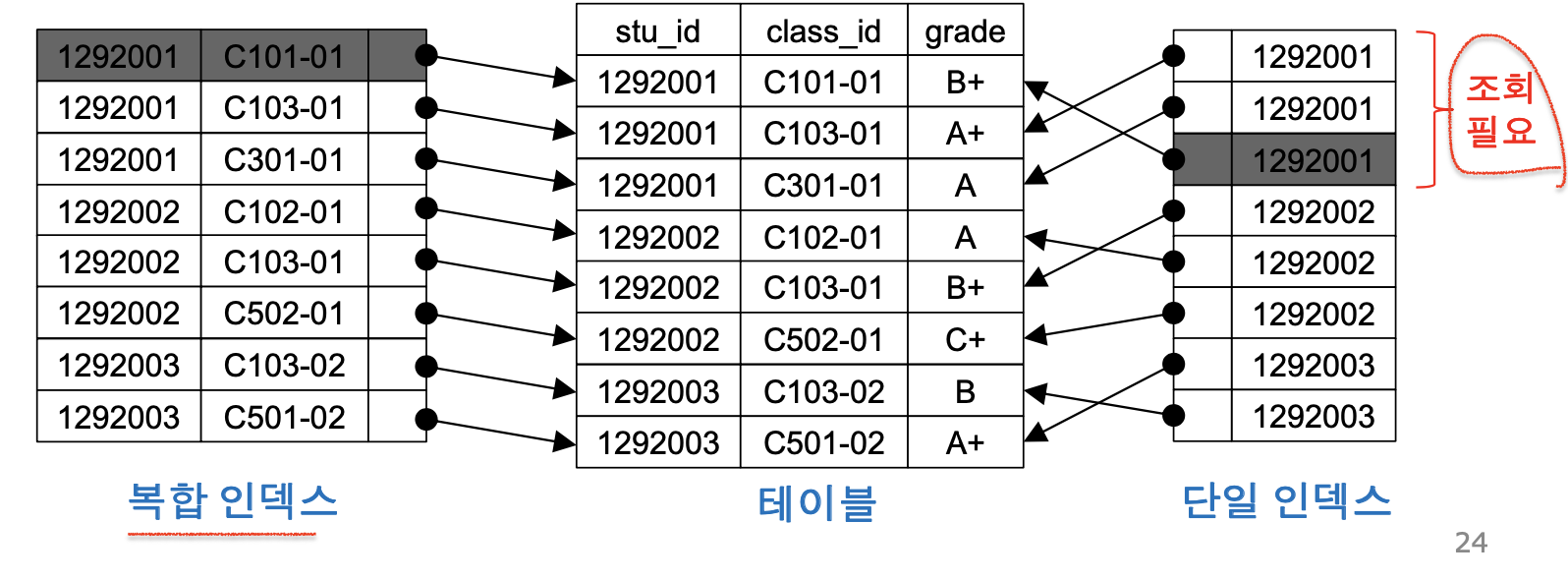
: 복합 인덱스가 정의된 필드만을 이용하는 질의는 테이블 조회 없이 복합 인덱스 조회만으로 처리 가능하다.
3) 복합 인덱스 주의사항
: 관련 필드의 순서에 따라 인덱스의 효과가 달라진다.
3. 해시 인덱스
: 해시 함수를 기반으로 인덱스 엔트리를 저장한 인덱스이다.
버켓(bucket)
: 인덱스 엔트리가 저장되는 공간이다. 블락보다는 큰 개념
: 해시함수 값을 버켓 번호로 사용한다.

1) 인덱스 구성 방법
: 인덱스 구성에 사용될 검색 키 필드를 설정한다.
: 레코드의 필드 값에 해시 함수를 적용하여 버켓 번호를 생성한다.
2) 인덱스 사용 방법
: 검색할 필드 값을 해시 함수에 적용하여 버켓 번호를 생성한다.
해당 버켓 안에 들어있는 인덱스 엔트리들 중 원하는 필드 값을 포함한 엔트리를 검색한다.
엔트리에 포함된 레코드 주소를 이용한다.
3) 해시 함수
: 해시 값은 입력값에 상관없이 균등하게 분포되어야 한다.
해시 함수의 예
H(x) = x % N

4) 버켓 오버플로우
: 일반적으로 버켓의 크기는 고정되어 있다.
: 버켓에 엔트리가 다 차는 경우 오버플로우가 발생한다.
: 새로운 버켓을 생성하여 기존 버켓과 연결해야 한다. (bucket chaining)
: 오버플로우가 많이 발생할수록 인덱스 성능이 저하된다.
4. B+ tree 인덱스 vs 해시 인덱스
1) 해시 인덱스
: 동등 비교 조건을 갖는 검색에 유리하다. (=)

2) B+ tree 인덱스
: 범위 조건을 포함한 검색에 유리하다. (<=, >=)
-> 검색 키 순서대로 정렬 및 연결되어 있기 때문이다.

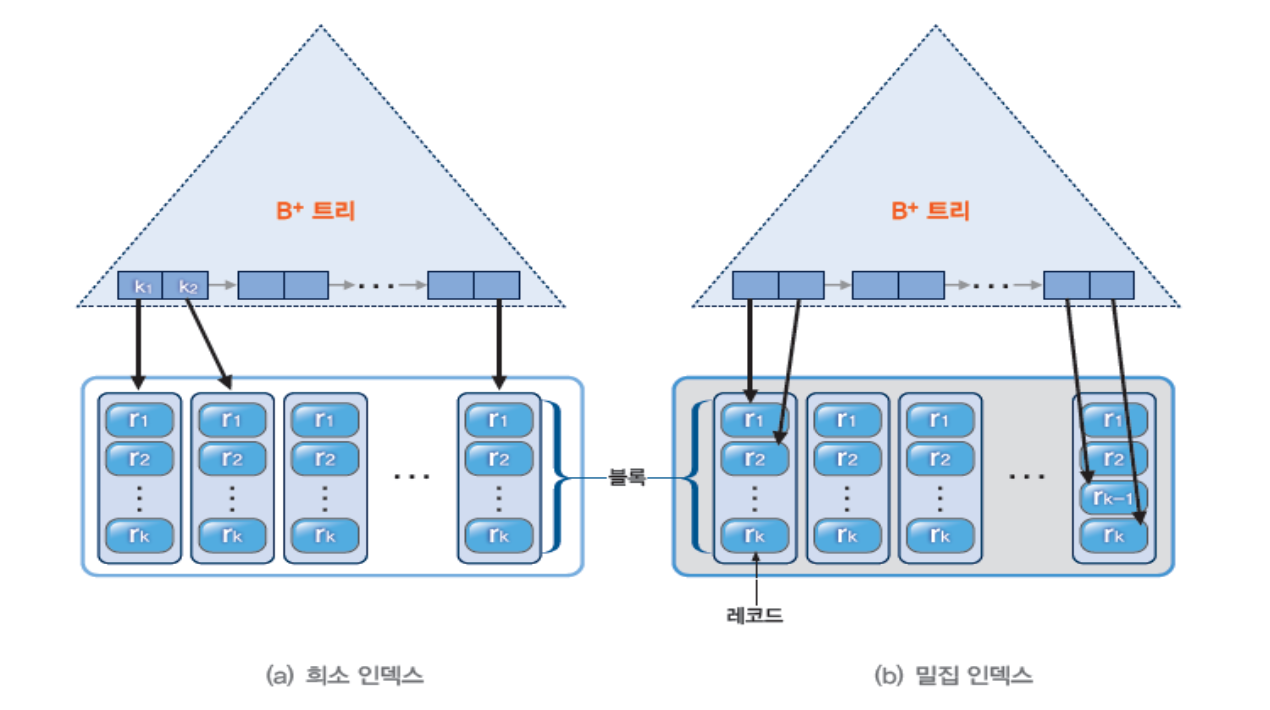
5. 인덱스 분류
- 대응 밀집도에 따라
1) 희소 인덱스
: 테이블의 일부 코드에 대해서만 인덱스 엔트리를 생성한다,
2) 밀집 인덱스
: 테이블의 모든 코드에 대해서 인덱스 엔트리를 생성한다,
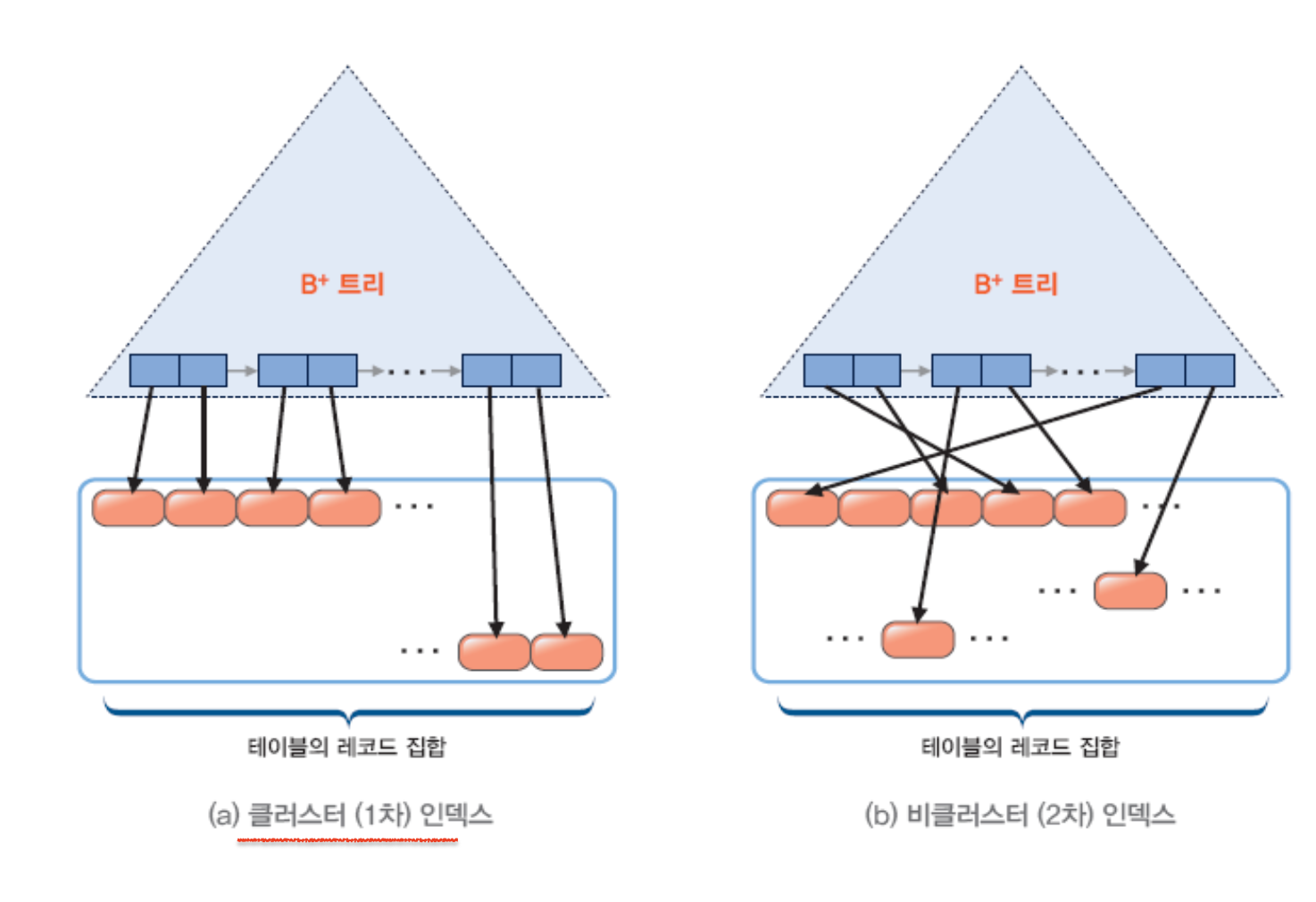
- 클러스터링 유무에 따라
1) 클러스터 인덱스
: 인덱스가 설정된 필드 값의 순서대로 레코드들이 인접하여 저장된다.
- 주로 기본 키에 대해 설정된다.
- 희소 인덱스 또는 밀집 인덱스 형태 모두 가능
2) 비클러스터 인덱스
: 인덱스 필드 값의 순서가 레코드들의 물리적 저장 위치와 무관하다.
: 반드시 밀집 인덱스 구조를 가진다.
6. 클러스터 인덱스
: 범위 조건 검색에 효과적이다.

: 정렬을 포함하는 질의에 효과적

7. 오라클의 인덱스 생성 구문
1) 일반 인덱스

예)
CREATE INDEX DEPT_INDEX ON DEPARTMENT(DEPT_NAME)
- dept_name의 값이 중복되지 않은 경우
CREATE UNIQUE INDEX DEPT_INDEX ON DEPARTMENT (DEPT_NAME)
2) 복합 인덱스

1)
CREATE INDEX STU_INDEX2 ON STUDENT(NAME, ADDRESS)
3) 인덱스 삭제

DROP INDEX DEPT_INDEX
8. 언제, 어디서 인덱스를 만들어야 할까?
<유리한 경우>
- 테이블 레코드 수가 많을 때
- where 절에 자주 사용되는 필드일 때
- 조인 연산에 참여하거나 널이 많은 필드일 때
<불리한 경우>
- 테이블 레코드 수가 적을 때
- where 절에 거의 사용되지 않는 필드
- 삽입, 삭제, 수정이 자주 발생하는 테이블
- 서로 구별되는 유일 값의 개수가 적은 필드
: 여러 레코드들이 동일한 값을 가지므로 질의의 선택도가 낮음
'Computer Science > Database' 카테고리의 다른 글
| 데이터베이스 설계 7)-2 동시성 제어 (0) | 2020.12.09 |
|---|---|
| 데이터베이스 설계 7) 트랙잭션 (0) | 2020.12.08 |
| 데이터베이스 설계 6)-2 물리적 저장구조와 인덱스 (0) | 2020.12.08 |
| 데이터베이스 설계 6) 물리적 저장구조와 인덱스 (0) | 2020.12.02 |
| 데이터베이스 설계 5) 정규형 (0) | 2020.12.01 |