!! 스케줄링 알고리즘 !!
1. 선입선처리 스케줄링(FCFS)
: 프로세스를 요구 순서대로 할당합니다.(First Come First Served)
- 비선점 기법 으로 스케줄링 알고리즘 중에 가장 간단합니다.
- 선입선출 큐로 구현합니다.
- 일괄처리에는 효율적, 대화식 시스템에서는 사용자의 빠른 응답 요구에 부적합


1) 평균 반환시간 : (24 + 27 + 30) / 3 = 27
2) 평균 대기시간 : (0 + 24 + 27) / 3 = 17
3) CPU이용률 : 100%
4) 처리량(작업처리율) : 3 / 30 = 10%
5) 평균 반응시간(응답시간) : (0 + 24 + 27) / 3 = 17

1) 평균 반환시간 : (3 + 6 + 30) / 3 = 13
2) 평균 대기시간 : (0 + 3 + 6) / 3 = 9
3) CPU이용률 : 100%
4) 처리량(작업처리율) : 3 / 30 = 10%
5) 평균 반응시간(응답시간) : (0 + 3 + 6) / 3 = 3
2. 최단 작업 우선 스케줄링
: CPU 버스트 시간이 가장 짧은 작업에 CPU를 할당합니다.
- 평균 대기시간을 최소화하는 알고리즘입니다.
- 문제점 : 실행 시간의 길이 예측이 힘듭니다. -> 실제로 실행하면 실행시간이 달라질수도 있기 때문입니다.


1) 평균 반환시간 : (3 + 9 + 16 + 24) / 4 = 13
2) 평균 대기시간 : (0 + 3 + 9 + 16) / 4 = 7
3) CPU이용률 : 100%
4) 처리량(작업처리율) : 4 / 24 = 0.167
5) 평균 반응시간(응답시간) : (0 + 3 + 9 + 16) / 4 = 7
- 최단 작업 우선 스케줄링은 선점 또는 비선점 모두 가능합니다.
(선점 : 매번 프로세스가 도착할 때마다 최단 작업을 비교하여 더 짧은 작업이 있다면 해당 작업으로 변경합니다.)
(비선점 : 한 프로세스가 끝난 뒤에 남은 것들끼리 비교하여 할당합니다.)


(a) 선점 -> 문맥교환하는 데 시간이 소요됨
- 평균 반환시간 : { (17-0) + (5-1) + (26-2) + (10-3) } / 4 = 13
- 평균 대기시간 : { (10-1) + (1-1) + (17-2) + (5-3) } / 4 = 6.5
- CPU이용률 : 100%
- 처리량(작업처리율) : 4 / 26 =
- 평균 반응시간(응답시간) : (0 + 0 + (17-2) + (5-3)) / 4 =
(b) 비선점
- 평균 반환시간 : { (8-0) + (12-1) + (26-2) + (17-3) } / 4 = 14.25
- 평균 대기시간 : { 0 + (8-1) + (17-2) + (12-3) } / 4 = 7.75
- CPU이용률 : 100%
- 처리량(작업처리율) : 4 / 26 =
- 평균 반응시간(응답시간) : (0 + (8-1) + (17-2) + (5-3)) / 4 = 7.75
3. 우선순위 스케줄링
: 최고 우선순위 프로세스를 CPU에 할당합니다.
: 최단 작업 우선 스케줄링은 우선순위 스케줄링에 해당합니다.
: 선점, 비선점에 모두 적용 가능합니다.
문제)
: 기아 상태가 발생가능합니다.
(기아 상태란? 우선순위가 높은 프로세스들이 계속 들어오면 우선순위 낮은 프로세스들은 무한정 기다려야 하는 상태)
해결법)
: 에이징(Aging) - 오랫동안 시스템에서 대기하는 프로세스들의 우선순위를 점진적으로 증가시키는 방법입니다.

-> 선점과 비선점 모두 같은 그림이 나옵니다.
1) 평균 대기시간 : (0 + 1 + 6 + 16 + 18) / 5 = 8.2
4. 라운드 로빈 스케줄링 [ 순환 할당 스케줄링 ]
: 시분할 시스템을 위해 설계되었습니다.
: 규정 시간량이 지나면 인터럽트가 발생하며 문맥교환을 수행합니다.�
: 준비큐는 FIFO 큐이면 순환큐로 설계합니다.
 순환큐 예시
순환큐 예시
 라운드 로빈 스케줄링
라운드 로빈 스케줄링
평균 반환시간 = { (16-1) + (8-1) + (26-2) + (25-3) } / 4
- 순환 할당 스케줄링은 선점 알고리즘입니다.
- 성능은 규정 시간량에 영향을 받습니다.
if 규정 시간량이 아주 클 경우, 평균 대기시간이 길어집니다.
if 규정 시간량이 매우 작을 경우, 문맥교환 횟수가 증가합니다.
-> 최적 규정 시간량은 시스템 특성 및 오버헤드, 프로세스에 따라 다릅니다.
- 반환시간도 규정 시간량에 영향을 받습니다.
if 규정 시간량이 매우 작을 경우, 반환시간이 증가합니다.
but 반환시간과 규정 시간량이 항상 반비례한 것은 아닙니다.

5. 다단계 큐 스케줄링�
: 각 작업들을 서로 다른 묶음으로 분류할 수 있을 때 사용합니다.
: 준비상태의 큐를 종류별로 여러 단계로 분할합니다.
: 각 큐는 자신만의 독자적인 스케줄링 알고리즘을 가집니다.
: 큐들 사이에 시간을 나누어 사용가능합니다.
 큐 5개를 가진 다단계 큐 스케줄링 알고리즘
큐 5개를 가진 다단계 큐 스케줄링 알고리즘
- 각 큐는 순서대로 절대적인 우선순위를 가집니다.
- 앞의 세 가지 큐가 비어있어야, 네 번째 일과 처리 큐에 있는 프로세스가 실행이 됩니다.
6. 다단계 피드백큐 스케줄링
다단계 큐 : 작업이 시스템에 들어가면 한 큐에서만 고정
다단계 피드백큐 : 작업이 큐 사이를 이동 가능
-> 기아 상태 예방을 위해 에이징 방법을 활용합니다.
: 특정 큐에서 오래 기다린 프로세스를 우선순위가 높은 큐로 이동합니다.

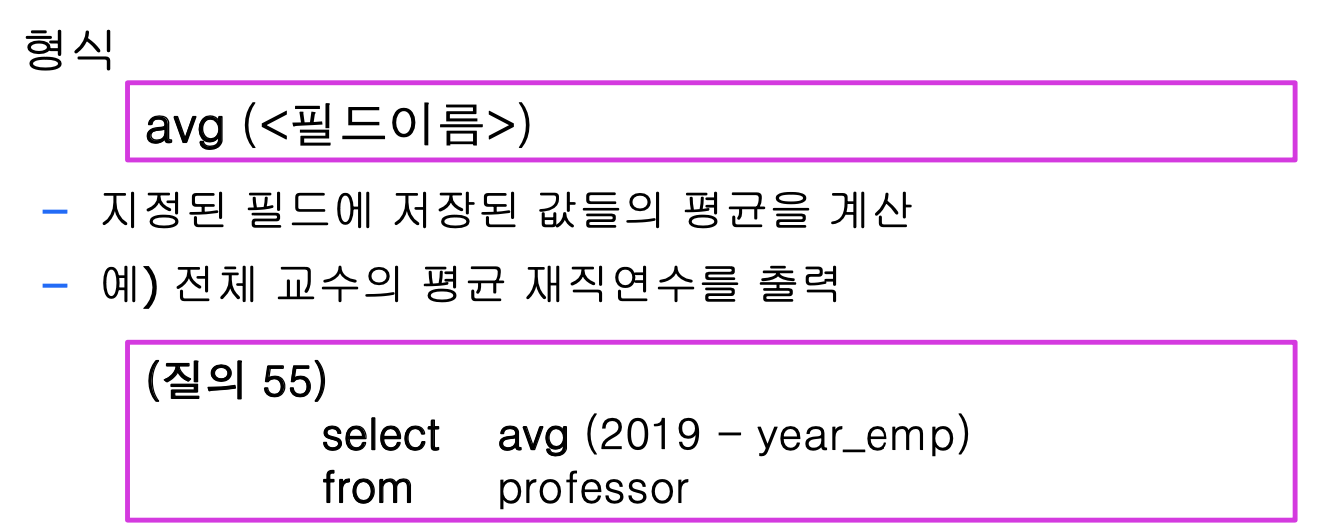
7. HRN 스케줄링(Highest Response-rate Next)
: 단기 작업 우선 스케줄링의 약점인 긴 작업과 짧은 작업 간의 불평등을 보완한 기법입니다.
: 가변적인 우선순위를 갖는 단기 작업 우선 스케줄링입니다.
 가변적 우선순위 계산법
가변적 우선순위 계산법
- 비선점 알고리즘입니다.
* 정보처리기사 문제풀어보기 *
1. 선점 기법 : 문맥교환으로 인해 많은 오버헤드 초래
2. 비선점 기법 : 모든 프로세스 요구 공정히 처리, 응답시간예측 용이,
CPU 사용시간 짧은 프로세스가 긴 프로세스들로 인해 오래기다림
3. 라운드 로빈 -> 시분할 시스템
4. HRN 방식 : 서비스 시간이 짧고, 대기 시간이 긴 순서대로
5. 응답시간 줄이고 CPU 이용률 높이고