# FCN
논문 링크 입니다.
https://arxiv.org/abs/1411.4038
Fully Convolutional Networks for Semantic Segmentation
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build
arxiv.org
# Semantic Image Segmentation이란?
Semantic Image Segmentation의 목적은 사진에 있는 모든 픽셀을 해당하는 (미리 지정된 개수의) class로 분류하는 것입니다. 이미지에 있는 모든 픽셀에 대한 예측을 하는 것이기 때문에 dense prediction 이라고도 불립니다.
여기서 주의해야하는 점은 semantic image segmentation 은 같은 class의 instance 를 구별하지 않는다는 것입니다. 쉽게말해서, 밑에 가족사진처럼 같은 class 에 속하는 object (사람이 4명)가 있을 때

사람을 따로 분류하지 않고, 그 픽셀 자체가 어떤 class 에 속하는지에만 관심이 있습니다 (오른쪽 사진). 왼쪽 사진처럼 instance 를 구별하는 모델은 따로 instance segmentation 이라고 불립니다.
단순히 사진을 보고 분류하는것에 그치지 않고 그 장면을 완벽하게 이해해야하는 높은 수준의 문제입니다.

# 들어가기 전에
**CNN Architecture: 전체 구조**

**CNN Architecture: 대표적 레이어 유형**
CNN에는 여러 종류의 계층이 있습니다.
그 중에 대표적인 레이어 유형은 다음과 같습니다.

1) **Convolutional layer**━"필터"는 이미지를 통과하여 한 번에 몇 Pixel(NxN)을 스캔하고 각 형상이 속하는 클래스를 예측하는 형상 맵을 만듭니다.

2) **Pooling layer (downsampling)**━가장 중요한 정보를 유지하는 동시에, 각 피쳐의 정보량을 줄입니다(대개 여러 개의 회전이 있습니다).
**[출처]** [[딥러닝 레이어] FC(Fully Connected Layers)이란?](https://blog.naver.com/intelliz/221709190464)|**작성자** [인텔리즈](https://blog.naver.com/intelliz)
# Abstract
CNN은 image recognition에 큰 발전을 가지고 왔습니다.semantic segmentation에도 CNN Deep learning model을 사용하기 위한 방법으로 FCN의 방법을 제시했습니다.
FCN은 AlexNet, VGG, GoogleNet과 같은 분류 모델을 적용하고, fine-tuning 함으로써 목적에 맞게 변형한 것입니다.
# 핵심 아이디어



정리해보자면,
- CNN으로 사진의 feature들을 추출하고, classifier 부분을 FC(fully connected layer)에서 CNN 부분으로 변경하여, 공간적 정보를 보존하고 image size에 상관 없이 입력 받을 수 있습니다.
- 사이즈가 작아진 activation map을 Upscaling을 이용해 원래의 input 이미지 크기를 가지도록 만들어주고, skip connection을 사용하여 깊은 network의 coarse한(거친) semantic 정보와 shallow, fine한 겉 모습의 정보를 합쳐주어 예측한 segmentation 결과를 출력할 수 있습니다.

# Introduction
FCN은 픽셀 단위의 예측(pixelwise prediction)을 수행합니다.
→ 네트워크 내의 upsampling layer는 *subsampled pooling을 통해 픽셀 단위의 예측을 가능하게 합니다.
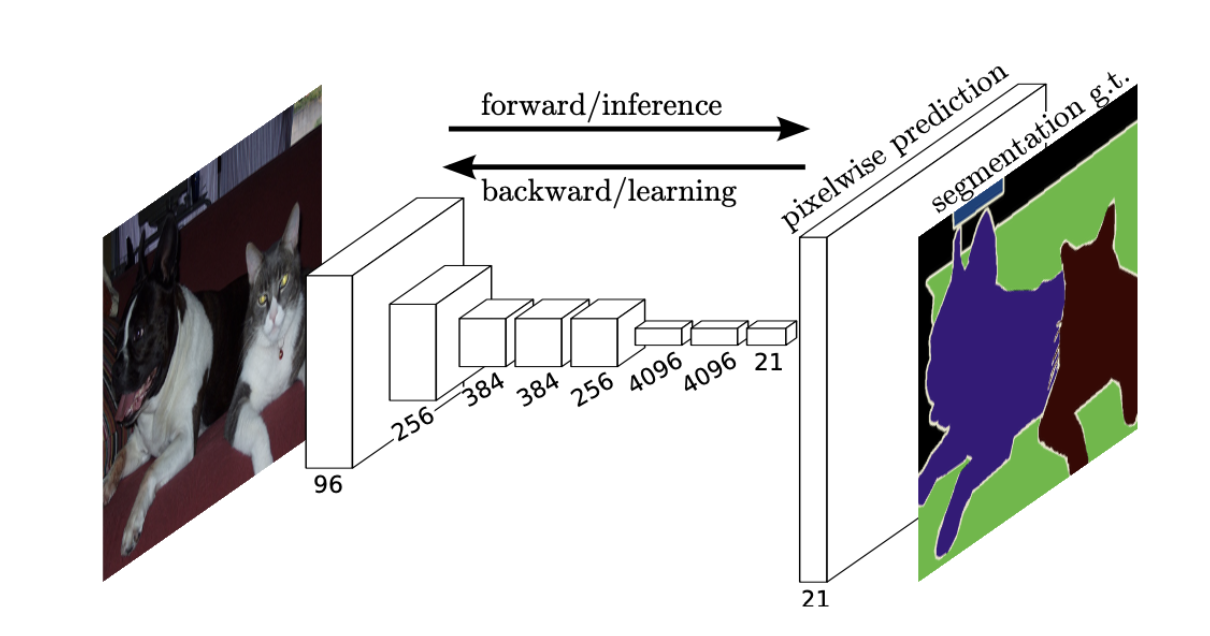
일반적인 CNN 같아 보이지만, 자세히 보시면 컨볼루션을 거친 뒤, 이를 쫙 펴서 FC에 넣어주는 것이 아니라, 1x1 컨볼루션을 계속 진행하는 것을 볼 수 있습니다. 그리고 이를 Upsampling 과정을 거쳐서 원래 이미지와 똑같은 크기의 피쳐맵을 만들어줍니다. 이 피쳐맵의 픽셀 하나하나를 classification 결과 값으로 하여 세그멘테이션을 진행하는 것입니다.
즉, 컨볼루션 레이어들만으로! Semantic Segmentation을 수행할 수 있게됩니다.
# Fully Convolutional networks
image recognition에서 일반적으로 사용하는 FC(Fully Connected layer) classfier를 CNN으로 바꿔주어 공간 정보를 보전하고 다양한 image size를 입력으로 받는 것
### 1. Adapting classifiers for dense prediction
LeNet, AlexNet과 같은 recognition 신경망은 fixed-sized 입력값을 받아서 공간정보가 없는 출력값을 생성합니다. 이러한 신경망의 Flatten → FC(Fully Connected layer) 부분에서 spatial 정보가 소실 되게 됩니다. 그래서 NIN(Network In Network, 1x1 Conv)로 FC(Fully Connected layer) 를 대체하여 spatial한 정보를 보존시켰다.
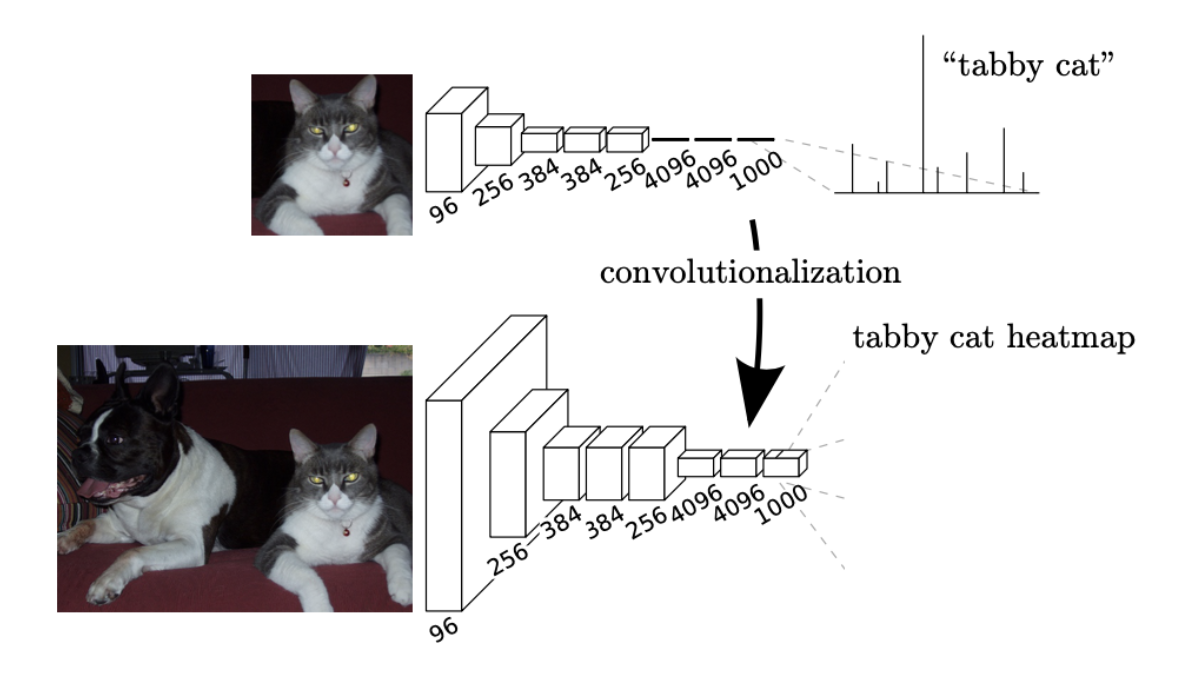
모든 layer에 Conv를 사용함으로서 ground truth를 각 layer의 출력을 얻을 수 있어 forward, backward passes가 간단해 효율적인 연산을 할 수 있다고 합니다.
- Ground Truth는 추론에 의해 제공되는 정보와 달리 직접 관찰 및 측정(즉, 경험적 증거)에 의해 제공되는 실제 또는 사실로 알려진 정보 를 참조하기 위해 다양한 분야에서 사용되는 용어
### 2. Shift-and-stitch is filter rarefaction
입력값이 conv + pooling을 통과하면 크기가 감소합니다. 이를 복원하는 방법으로 shift-and-stich 방법을 검토하는데, 이보다 skip connection을 사용한 upsampling이 더 효과적으로 판단하여 shift-and-stich 방법은 사용하지 않습니다
- shift-and-stich 방법 : max pooling을 하고 위치 정보를 저장하여 원래의 이미지 크기로 upscaling하는 방식, but 계산 비용이 큼
- Max pooling (맥스 풀링)
: 맥스 풀링은 Activation map을 MxN의 크기로 잘라낸 후, 그 안에서 가장 큰 값을 뽑아내는 방법이다.
### 3. Upsampling is backwards strided convolution
Convolutionalization을 통해 출력 Feature map은 원본 이미지의 위치 정보를 내포할 수 있게 되었습니다.
그러나 Semantic segmentation의 최종 목적인 픽셀 단위 예측과 비교했을 때, FCN의 출력 Feature map은 너무 **coarse(거친, 알맹이가 큰)** 합니다.
따라서 Coarse map을 원본 이미지 크기에 가까운 Dense map으로 변환해줄 필요가 있습니다.
1) backward strided convolution(=Deconvolution)과
2) bilinear interpolation을 사용합니다.
### 1) backward strided convolution(Deconvolution)
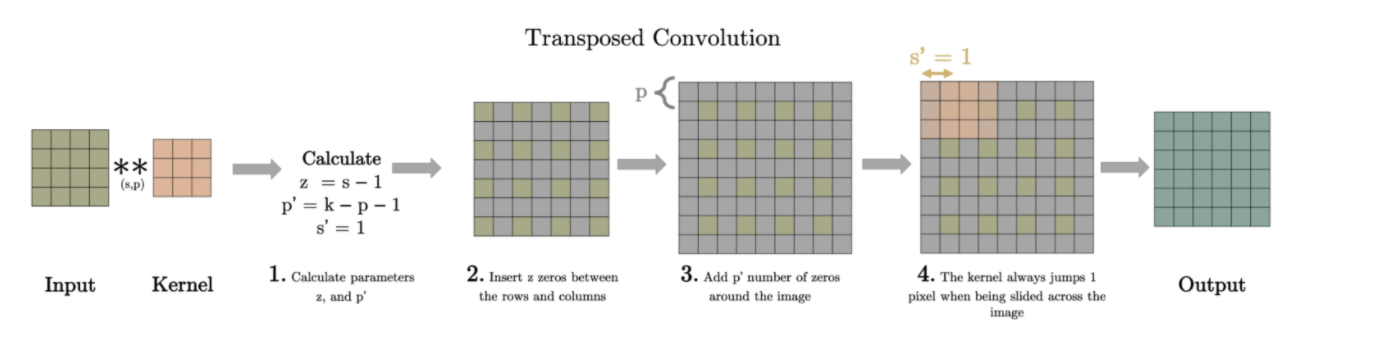
위와 같이 사이를 띄워주고 padding 해준 Input을 convolution하면 원하는 사이즈의 Output을 얻을 수 있다.
그래서 원래 이미지 사이즈로 Upsampling하면, pixelwise loss를 구할 수 있어서 backprop 하기가 용이하다.
### 2) bilinear interpolation
Bilinear interpolation을 이해하기 위해서는 Linear interpolation을 우선적으로 이해할 필요가 있다.
다음의 두 값을 예측해 보자.

위의 값은 5, 아래 값은 7 임을 어렵지 않게 예측할 수 있다. 이 처럼 두 지점 사이의 값을 추정할 때 직관적으로 사용하는 방법이 Linear interpolation이다.
위의 추정 방식은 다음과 같이 식으로 표현할 수 있다.

식을 앞의 예제에 대입하면 다음과 같이 추정값을 쉽게 구할 수 있다.
** bilinear interpolation은 이러한 1차원의 Linear interpolation을 2차원으로 확장한 것이다.

네 지점 A, B, C, D 사이의 임의의 점 X를 추정할 수 있다.
이제 우리는 다음과 같은 Feature map의 빈 영역을 추정할 수 있다.

### 4. Patchwise training is loss sampling
patchwise training과 fully convolutional training을 비교해서 설명합니다.
- Patchwise training란 하나의 이미지에서 객체가 존재하는 위치 또는 주변 위치를 crop하여 하나의 patch로 만든 뒤 모델에 입력하는 training 방식입니다.
→ Patchwise training을 사용하는 이유는 이미지에 필요 없는 정보들이 존재할 수 있고, 하나의 이미지에서 서로 다른 객체가 존재하는 경우 중복성이 발생한다(고양이에 관련된 feature를 추출해야하는데, 필요 없는 배경까지 모두 봐야 하는 문제)
→ 이미지에서 patch 이미지를 뽑아내서 필요한 부분을 위주로 training 시킬 수 있다. class imbalance 문제를 완화할 수 있지만 공간적 상관 관계가 부족해진다는 단점이 있다
→ patchwise training을 통해 하나의 이미지를 100개의 patch로 분할해 각 patch마다의 loss 값을 구하게 된다. 이 때, 모든 loss를 사용하는 것이 아니라 중요한 patch들의 loss만 사용하거나 가중치를 주어 loss 값을 샘플링해 사용할 수 있다고 한다.
- 반면에 fully convolutional training은 전체 이미지를 입력으로 받아 학습하는 것입니다.
→ 결과적으로는 patchwise training을 사용하지 않았습니다. whole image training이 dense prediction을 위한 training 속도 측면에서 더 효과적이고 효율적이었다고 합니다.
# Segmentation Architecture
FCN, Upsampling 그리고 pixelwise loss를 사용한 모델을 이용해 dense prediction을 구했습니다.
여기서 skip connection을 이용해 coarse, semantic 정보와 local, appearance 정보를 합친 개선 된prediction을 구했습니다.
### 1. From classifier to dense FCN
backbone은 VGG-16을 사용합니다. 그리고, 마지막 classifier layer를 버리고, 이것을 fully convolution으로 변경합니다. 원래 이미지 크기로 맞춰주기 위해 coarse output에 upsampling을 수행하는 deconvolution layer 이후의 coarse output locater에 21 차원을 가진 1x1 convolution을 추가합니다. 21차원은 배경을 포함한 *PASCAL classes를 예측합니다. channel을 PASCAL의 class 개수와 맞추기 위해 1x1 conv를 사용했다.
*Pascal VOC is a collection of datasets for object detection
VGG16을 예로 살펴보자. 다음과 같이 출력층 부분의 마지막 3 fc-layers를 모두 Conv-layers로 변경한다.

### 2. Combining what and where
segmentation을 위한 새로운 fully convolutional network를 정의합니다. layer를 결합하고 출력값의 공간적인 정보를 개선합니다.
*skip architecture

1x1인 pool5의 activation map을 32배 한 upsampled prediction을 FCN-32s라고 한다.
2x2인 pool4의 activation map과 pool5를 2x upsampled prediction을 더해, 16x upsampled prediction(FCN-16s)를 구했다.
이와 같이 4x4 pool3과 앞서 더해주었던 prediction을 합해 8x upsampled predicton(FCN-8s)를 구했다.

결과를 보면 low 레이어의 prediction을 더한 FCN-8s가 가장 디테일한 부분까지 가지고 있는 것을 확인할 수 있다.
또한 결과표를 봐도 FCN-8s의 결과가 가장 좋은 것을 확인할 수 있다.

'AI > 논문리뷰' 카테고리의 다른 글
| [Segmentation] Deep High-Resolution Representation Learning 논문 리뷰 (0) | 2022.05.17 |
|---|---|
| [Segmentation] Attention 논문 리뷰 (0) | 2022.05.16 |
| [Segmentation] 계층적 multi-scale HRNet-OCR attention 논문 리뷰 (0) | 2022.05.12 |
| [Detection] R-CNN 논문 리뷰 (0) | 2022.05.04 |
| [Classification] AlexNet 논문리뷰 (0) | 2022.05.02 |