논문 링크입니다.
https://arxiv.org/abs/1511.03339
Attention to Scale: Scale-aware Semantic Image Segmentation
Incorporating multi-scale features in fully convolutional neural networks (FCNs) has been a key element to achieving state-of-the-art performance on semantic image segmentation. One common way to extract multi-scale features is to feed multiple resized inp
arxiv.org
0. Title
Attention to Scale: Scale-aware Semantic Image Segmentation
-> 어텐션에서 스케일로.. 스케일을 아는 시맨틱 이미지 세그먼테이션
이 논문의 핵심은 어텐션 매커니즘과 스케일로 예측된다.
1. Abstract
FCN(Fully Convolutional Network)에 multi-scale feature을 적용한 것은
시맨틱 세그먼테이션에서 SOTA 성능을 달성하는데 핵심이 되었다.
multi-scale feature를 뽑는 데 일반적으로 사용되는 방법은
공유되는 deep network에 다수의 resize된 이미지를 먹이는 것이다.
그리고 나온 결과를 픽셀 단위로 합치는 것이다.
우리는 어텐션 매커니즘을 제안한다.
이는 각 픽셀 위치에서 다중 스케일 기능에 부드럽게 가중치를 부여하는 방법을 학습하는 메커니즘이다.
우리는 state-of-the-art segmentation model을 채택하였고, 여기에 우리의 어텐션 모델과 multi-scale input image를 학습하였다.
어텐션 모델은 average pooling 과 max pooling 의 성능을 능가할 뿐만 아니라,
다양한 위치와 스케일에서의 feature의 중요성을 진단적으로 시각화할 수 있게 하였다.
게다가, multi-scale features를 병합할 때 좋은 성과를 내려면
각 스케일의 output에 대한 추가적인 감독이 필요함을 보여준다.
우리의 모델의 효과성을 PASCAL-Person-Part, PASCAL VOC 2012 and a subset of MS-COCO 2014에서
입증하였다.
2. Conclusion
이 논문에서는 multi-scale input을 활용하기 위해 DeepLab-LargeFOV 모델을 사용하였다.
세가지 데이터셋에 실험해봄으로써 우리가 알아낸 것이다.
1) multi-scale inputs가 single-scale inputs 보다 더 좋은 성능을 냄
2) 어텐션 모델에 multi-scale features를 적용한 것은 average pooling과 max pooling보다 뛰어날 뿐만 아니라,
다른 위치와 스케일에 따른 features의 중요성을 진단적으로 시각화할 수 있다.
3) 각각의 스케일에 마지막 결과에 추가적인 감독이 있다면 훌륭한 결과가 있을 것이다.
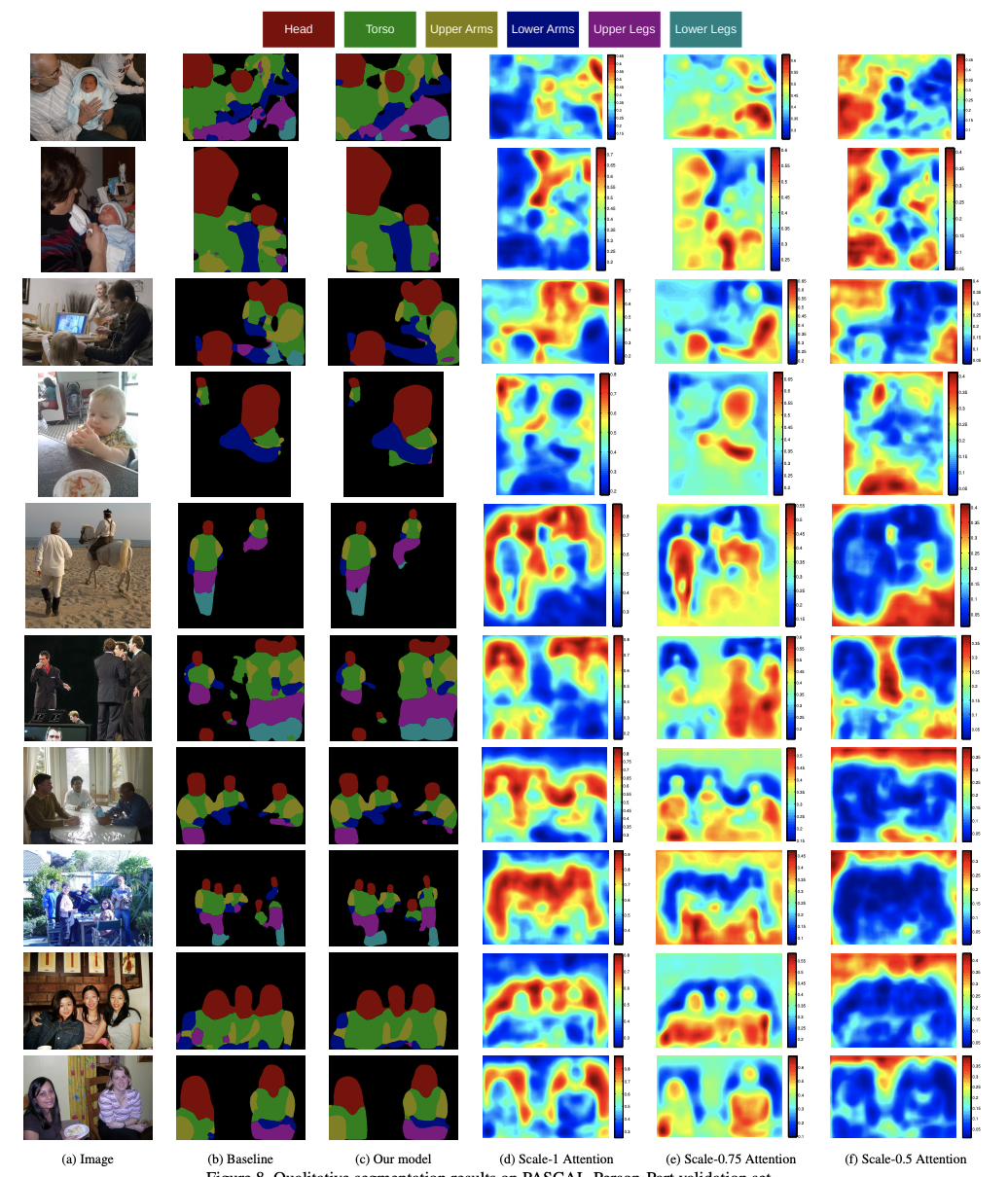
3. Introduction
Semantic image segmentation는 각각의 모든 픽셀에 semantic label을 할당하는 태스크이다.
최근에는 FCN 을 기반으로 한 다양한 방식들이 놀라운 성과를 내었다.
성공적인 Semantic image segmentation의 요소 중 한가지는 "multi-scale features"의 사용이다.
FCN에는 multi-scale features를 활용하는 두 가지 타입의 네트워크 구조가 있다.
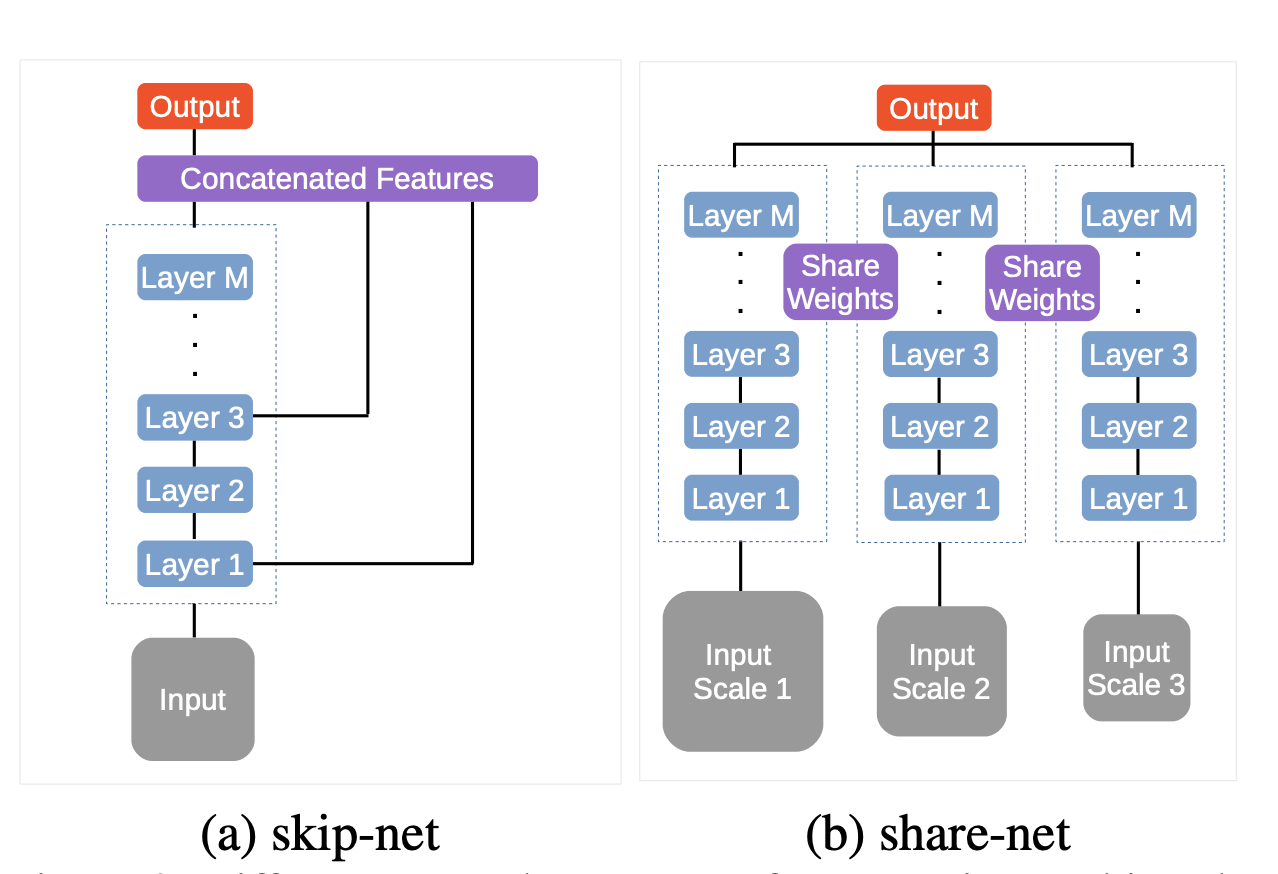
첫 번째는 skip-net이다.
아주 큰 receptive field sizes 때문에 skip-net의 feature는 본질적으로 multi-scale이다.
학습 시간동안 skip-net은 두 가지 프로세스를 거치는데,
딥러닝 백본을 학습하고, multi-scale feature extraction 과정에서 fine tuning하는 것이다.
이 전략의 문제점은 학습과 feature extraction 과정이 분리되어 있기 때문에 학습 과정이 이상적이지 못 하다는 것이다.
두 번째는 share-net이다.
인풋 이미지를 여러 사이즈로 리사이즈하고, 공유된 딥 뉴럴 네트워크로 통과하는 것이다.
그런 다음 다중 스케일 피쳐들을 기반으로 최종 예측값을 계산한다.
최근, attention model은 컴퓨터 비전과 자연어 처리에서 엄청난 성공을 하였다.
전체 이미지와 시퀀스들을 압축하는 것이 아니라, 어텐션은 가장 유용하고 관련있는 피쳐에 집중한다.
이전의 2D 대상으로한 어텐션 모델들과 다르게, 우리는 scale dimension에서의 효과를 입증해보고자 한다.
우리는 sota 모델에 share-net를 적용하였고,
average pooling과 max pooling을 generalize하기 위해 soft attention model을 적용하였다.
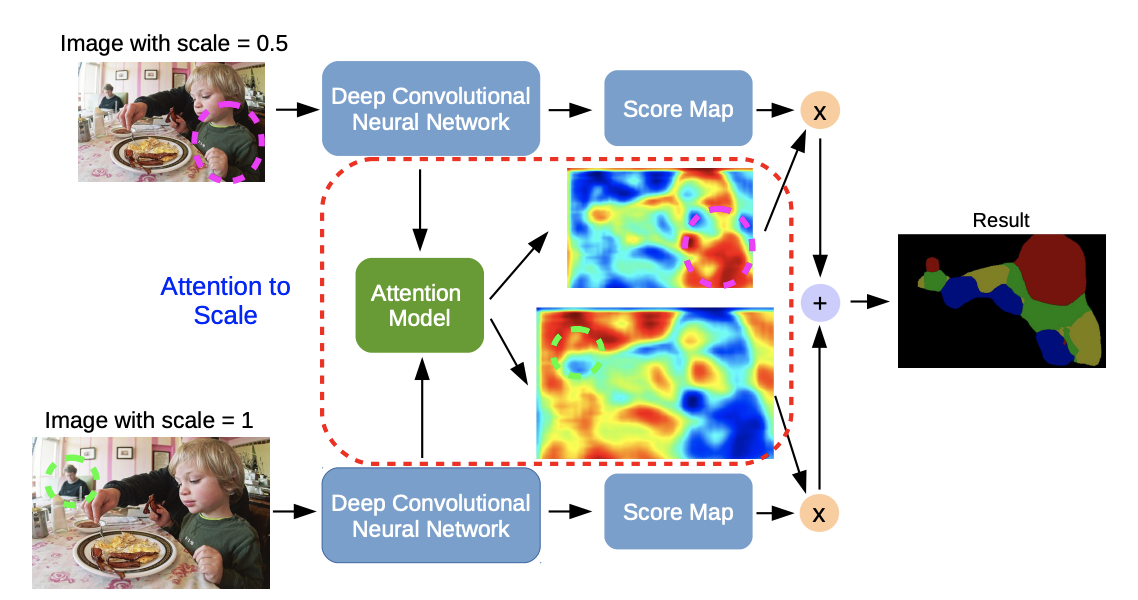
어텐션 모델은 이미지에 나타나 있는 물체의 크기에 따라
multi-scale feature들에 가중치를 부여하는 방법을 학습힌다.
(예를 들어, 모델은 거칠고 큰 물체에는 큰 가중치를 부여한다.)
각각의 스케일에서, 어텐션 모델은 weight map을 뱉어내는데, 이것은 픽셀 바이 픽셀로 가중치를 구한 것이다.
그리고 FCN에서 생성한 score map의 가중치 합을 뱉어낸다.
각각의 스케일마다 추가적인 감독을 소개한다. 성능 개선에 필수적인
우리는 어텐션 모델과 멀티스케일 네트워크를 공동으로 학습시킨다.
어텐션 컴포넌트는 average pooling과 max pooling에 비해 상당한 개선을 제공한다.
게다가 diagnostic visualization이 가능하다. 모든 이미지 포지션에서 각각의 스케일의 각각의 피쳐들의 중요성을 시각화함으로써 블랙박스를 벗겨내었다.
4. Model
1) Review of DeepLab
FCN이 semantic segmentation에서 성공적인 효과를 거두었으므로
FCN의 변형인 DeepLab 모델을 리뷰해보고자 한다.
DeepLab은 VGG를 참고하여 16개의 레이어 구조를 채택하였다.
해당 네트워크에 dense feature map을 가져다주는 fully convolution으로 주입하였다.
자세하게는, 마지막 VGG의 fully connected layer가 fully convolutional layer로 변경되었다. (마지막 레이어는 커널 사이즈 1x1)
원래의 VGG-16의 spatial decimation은 32이다. 5개의 stride 2를 가진 max pooling을 사용하였기 때문이다.
DeepLab은 atrous 알고리즘을 사용하여 이를 8로 줄였다.
또한 linear interpolation을 사용하여 최종 레이어의 스코어 맵을 원본 이미지 해상도에 매핑한다.
우리는 DeepLab의 여러가지 변형 중, DeepLab-LargeFOV에 초점을 맞춘다.
2) Attention model for scales
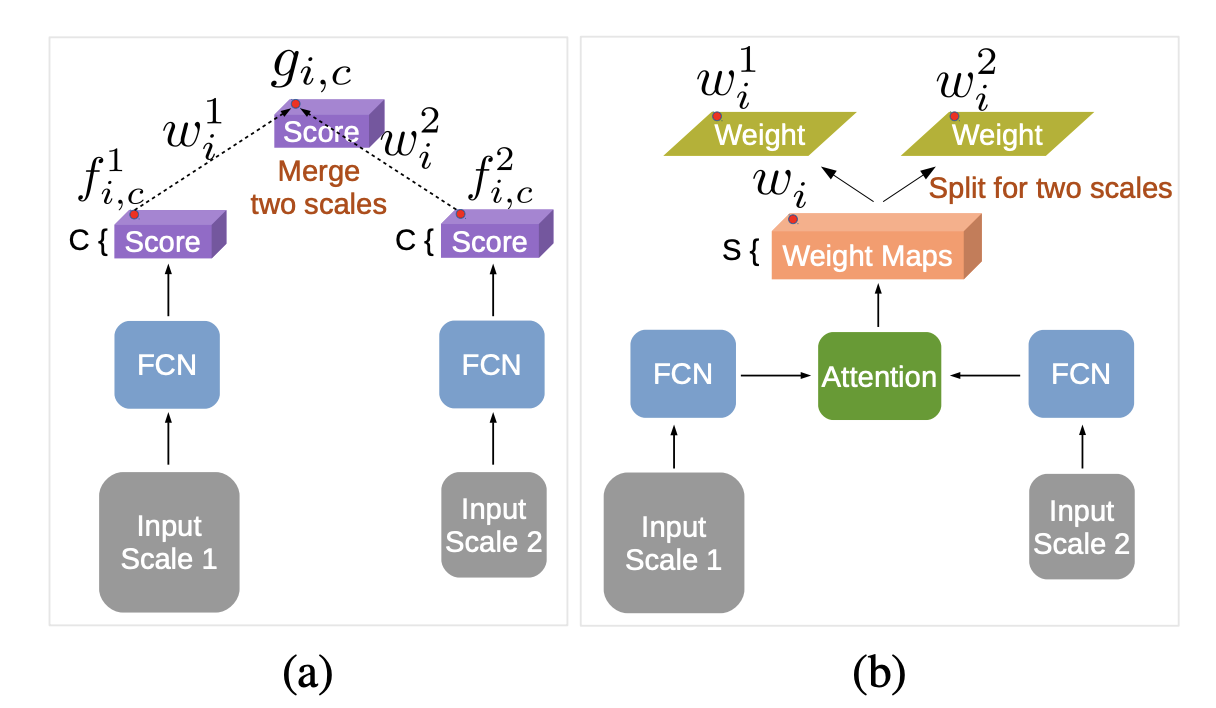
어텐션 모델은 각각의 다른 스케일과 position으로 부터 FCN이 생성한 스코어맵의
가중 합을 어떻게 할지를 반영하는 weight map을 만든다.
즉, multi-scale features를 가중치를 어떻게 할지 학습한다.
share-net을 기반으로, 인풋 이미지는 여러 스케일로 리사이즈 된다.
각각의 스케일은 DeepLab을 통과하며 score map을 만든다. (fully convolutional layer)
score map은 bilinear interpolation을 통해 동일한 해상도를 갖도록 리사이즈된다.
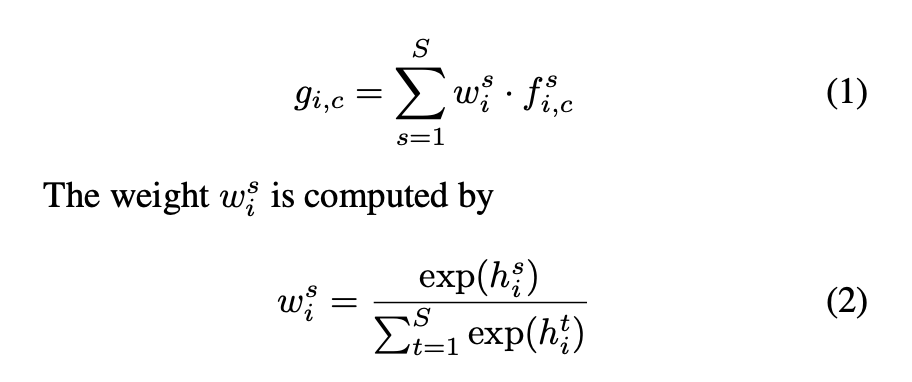
f : score map
w : importance of feature at position i and scale s
g : weighted sum of score map
w를 시각화하면 스케일별로 어텐션을 시각화할 수 있다.
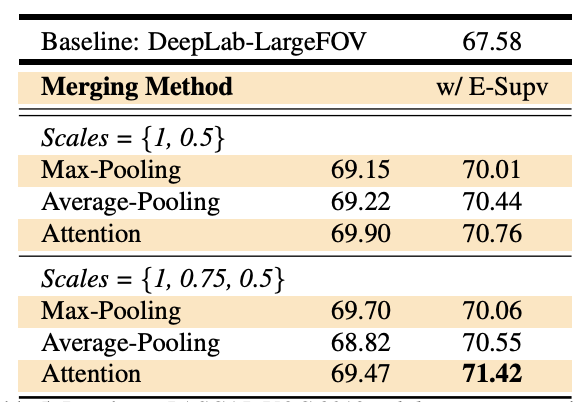
5. Result
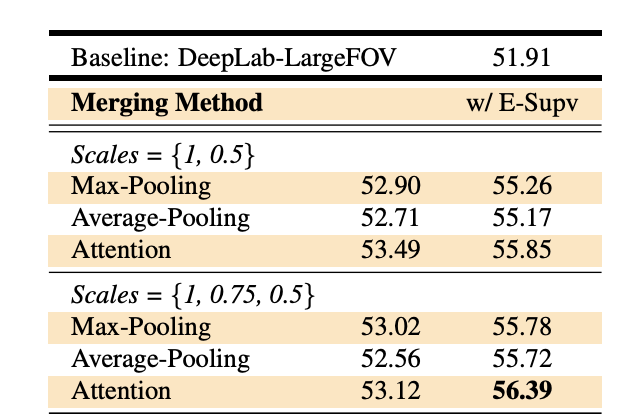

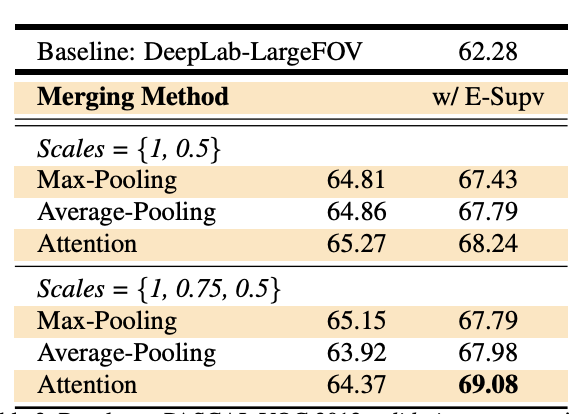
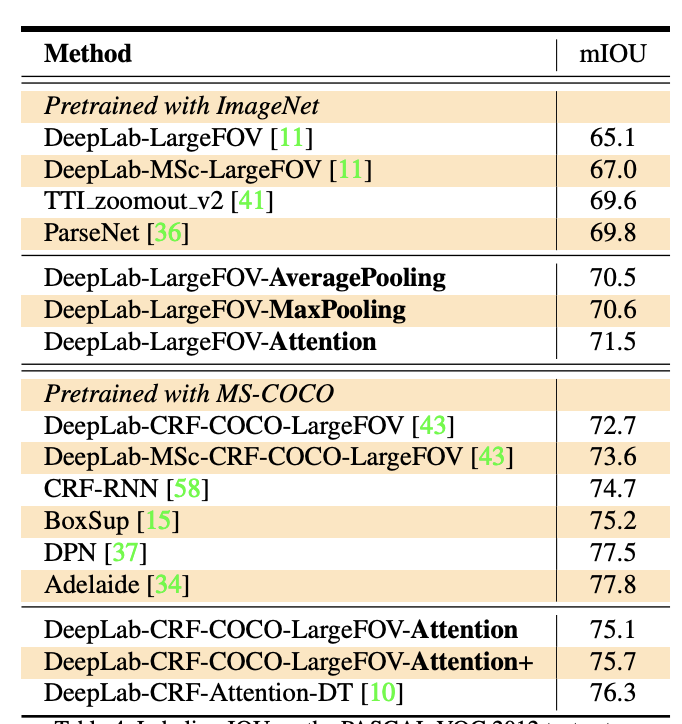
'AI > 논문리뷰' 카테고리의 다른 글
| [Segmentation] Segmentation Transformer: Object-Contextual Representations 논문 리뷰 (0) | 2022.05.20 |
|---|---|
| [Segmentation] Deep High-Resolution Representation Learning 논문 리뷰 (0) | 2022.05.17 |
| [Segmentation] 계층적 multi-scale HRNet-OCR attention 논문 리뷰 (0) | 2022.05.12 |
| [Segmentation] FCN 논문 리뷰 (0) | 2022.05.10 |
| [Detection] R-CNN 논문 리뷰 (0) | 2022.05.04 |