백트래킹이란 무엇인가?
다시금 정의를 써보면 백트래킹은 구하고자 하는 해를 튜플로 나타내고 튜플에 기준 함수(한정 함수)를 적용했을 때의 결과가 최대치, 최소치 혹은 일정 조건을 만족하게끔 만들어주는 퇴각 검색 기법으로 정의된다.
백트래킹의 목표
상태 공간 트리를 DFS로 탐색하여 해결 상태에 도달하는데 있어 불필요한 탐색을 하지 않는 것을 목표로 한다.
Sum of Subset 문제에서 나올 수 있는 조합의 모든 경우의 수를 전체 탐색을 통해 확인한다면 집합

에 대해 |S| = n 일 때, 2^n 의 경우의 수를 탐색해야 한다. 즉, 시간 복잡도가 Ω(2^n) 이 되어 매우 비효율적인 탐색이 된다.
백트래킹 과정
백트래킹은 상태 공간 트리를 탐색하는 것을 전제로 한다.
(x[1], x[2], ..., x[k]) : 1~k번째 단계에서 선택된 노드들을 순서대로 튜플로 표현한다.
T(x[1], ... x[k-1]) : (x[1], ..., x[k])의 튜플의 경로가 상태 공간 트리에 속하도록 하는 모든 x[k]의 집합이다. 즉, (x[1], ..., x[k-1]) 의 경로에서 x[k-1]의 자식 노드들을 x[k]라고 한다.
이 문제에서 예시를 드는 Sum of Subset 문제는 n=4, S={5, 9, 11, 20}, m=25 라 가정한다.
1. 문제 상황을 상태 공간 트리로 표현한다.
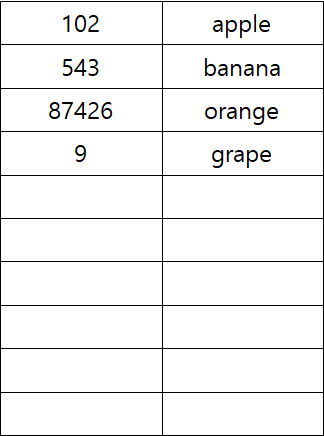
Sum of Subset의 경우 아래 그림과 같이 집합의 각 원소의 선택 여부로 상태 공간 트리를 표현할 수 있다.
이때 명시적 제약조건은 다음과 같다.
명시적 제약 조건 : 트리의 각 노드는 0 또는 1의 값을 가진다. 이때 i번째 높이의 노드는 i번째 원소의 선택 여부를 나타내며 0은 선택하지 않음, 1은 선택함을 나타낸다.

[그림1]
2. 루트 부터 DFS를 하여 불필요한 탐색을 하지 않고 한정 함수를 만족하는 (x[1], x[2], ..., x[n])를 찾는 것을 목표로 한다.
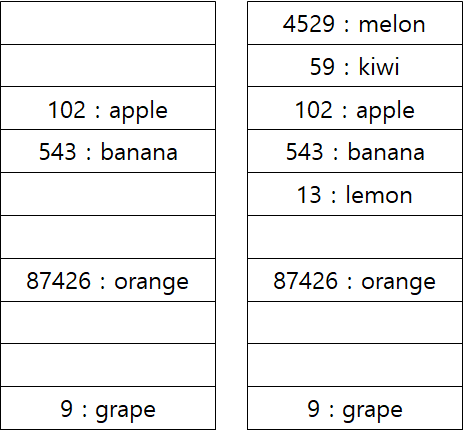
아래 [그림 2]는 Sum of Subset 문제에서 DFS 후 정답 25가 만들어지는 부분집합 {5. 25}를 찾아낸 상황이다.

[그림 2]
3. 각 노드 s 에 도착할 때마다 루트에서 s까지의 경로 예를 들어 k번째 선택에선 (x[1], x[2], ..., x[k])의 튜플이 한정함수를 만족하는지 판단한다.
한정 함수는 암시적 제약 조건의 참/거짓 여부를 판별하는 함수이다.
Sum of Subset의 경우 집합의 원소의 개수가 n이고 원하는 부분집합의 합이 m일 때 암시적 제약 조건은 다음과 같다.
암시적 제약 조건 : w[i]를 집합에서 i번째 원소라고 가정하면 한정함수

을 만족하면 참을 반환한다.

4-1. (x[1], x[2], ..., x[k])의 튜플이 한정 함수를 만족한다면 x[k] 노드를 live node이자 e-node로 변경한다.

4-2. 한정함수를 만족하지 않는 다면 T(x[1], ... x[k])의 노드들을 더이상 확장하지 않으며 dead node로 만든다.

5. k < n 일때 x[k]의 자식 노드들인 x[k+1] 들 즉, T(x[1], ... x[k])을 탐색한다.

6. 모든 자식 노드를 탐색했다면 현재 노드를 dead node로 변경한다.

7. 진행 도중 한정함수를 만족하는 (x[1], x[2], ..., x[n])에 도달하면 정답을 출력한다.

8. 정답이 도출되었거나 모든 노드가 dead 노드가 되었다면 탐색을 종료한다. 이때 정답이 여러개 인 경우에 모든 정답을 찾고 싶다면 모든 노드가 dead 노드가 될때까지 탐색해야 한다.

백준 문제 적용
https://www.acmicpc.net/problem/2580
2580번: 스도쿠
스도쿠는 18세기 스위스 수학자가 만든 '라틴 사각형'이랑 퍼즐에서 유래한 것으로 현재 많은 인기를 누리고 있다. 이 게임은 아래 그림과 같이 가로, 세로 각각 9개씩 총 81개의 작은 칸으로 이루
www.acmicpc.net
package com.company;
import java.io.BufferedWriter;
import java.io.OutputStreamWriter;
import java.util.ArrayList;
import java.util.Scanner;
public class Ans {
static ArrayList<int[]> empty_spots = new ArrayList<>();
static int[][] matrix = new int[9][9];
public static void main(String [] args){
BufferedWriter buf = new BufferedWriter(new OutputStreamWriter(System.out));
Scanner sc = new Scanner(System.in);
for(int i=0; i<9; i++){
for(int j=0; j<9; j++) {
matrix[i][j] = sc.nextInt();
if (matrix[i][j] == 0) {
empty_spots.add(new int[]{i, j});
}
}
}
sudoku(0);
EDA();
}
static boolean sudoku(int count){
if(count == empty_spots.size()){
return true;
} else {
int [] position = empty_spots.get(count);
int n = position[0];
int m = position[1];
for(int i=1; i<10; i++){
if(isPromising(matrix, n, m, i)){
matrix[n][m] = i;
if(sudoku(count+1)) return true; // 끝에 도달했으면 return true
else matrix[n][m] = 0; // 백트래킹
}
}
}
return false; // 중요
}
static boolean isPromising(int[][] matrix, int n, int m, int num){
int len = matrix.length;
int n_block = (n / 3) * 3;
int m_block = (m / 3) * 3;
for(int i=0; i<len; i++){
if(matrix[n][i] == num) return false;
if(matrix[i][m] == num) return false;
}
for(int i=0; i<3; i++){
for(int j=0; j<3; j++){
if(matrix[n_block + i][m_block + j] == num) return false;
}
}
return true;
}
public static void EDA(){
for(int i=0; i<9; i++){
for(int j=0; j<9; j++){
System.out.print(matrix[i][j]);
System.out.print(' ');
}
System.out.println();
}
}
}
출처: https://it00.tistory.com/26 [IT]
'Programming > Coding Test' 카테고리의 다른 글
| Arrays.sort(), StringBuilder 18870 좌표압축 (0) | 2021.12.04 |
|---|---|
| 백트래킹 알고리즘, 백준 14889 스타트와 링크 (0) | 2021.12.03 |
| [알고리즘 정리] 벨만포드, 플로이드와샬 알고리즘 (0) | 2021.05.13 |
| [알고리즘 정리] 다익스트라 알고리즘 (0) | 2021.05.10 |
| [알고리즘 정리] 동적계획법 (DP) (0) | 2021.05.08 |