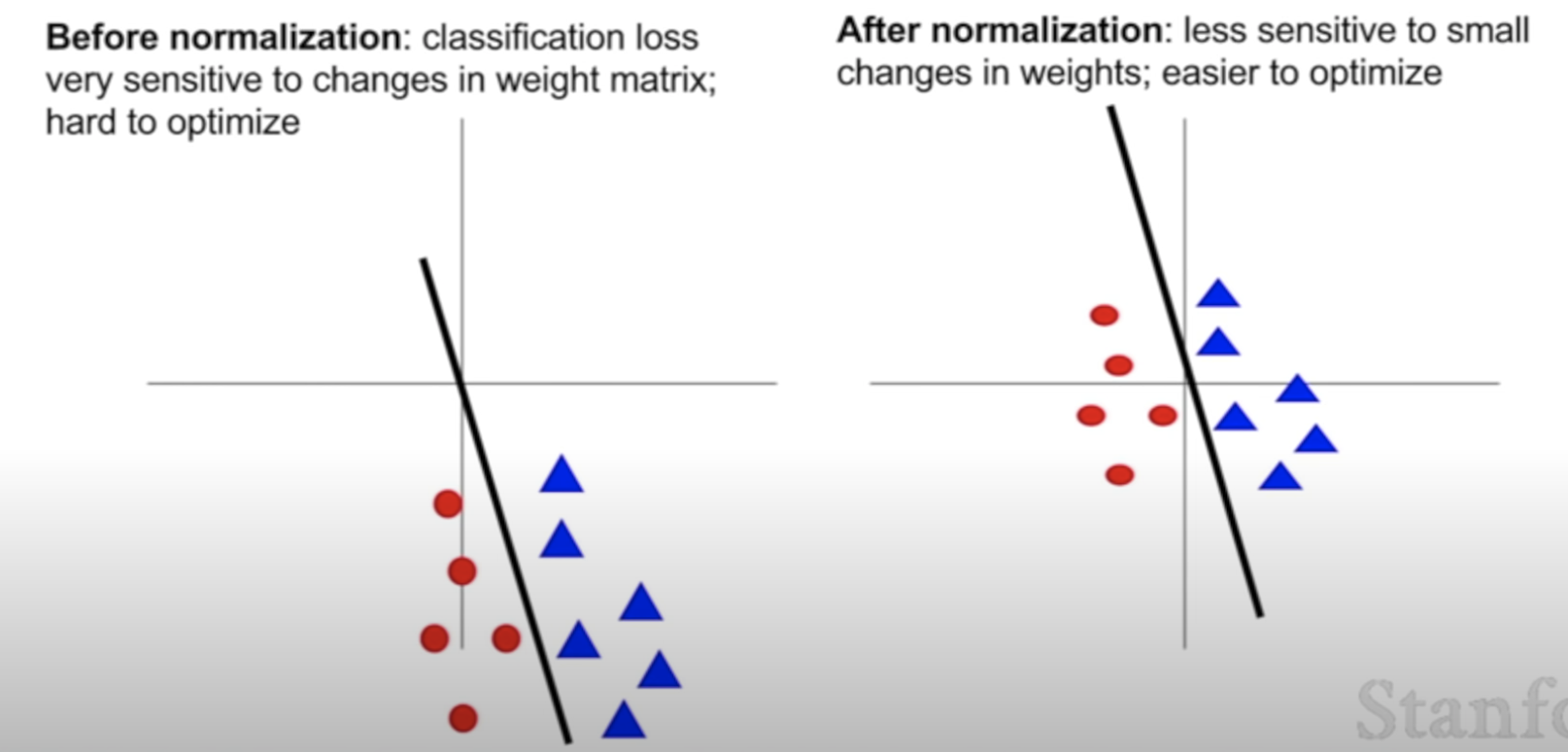
Lecture 2 Word Vectors, Word Senses, and Neural Network Classifier
# Word2vec parameters and computations
### bag of words
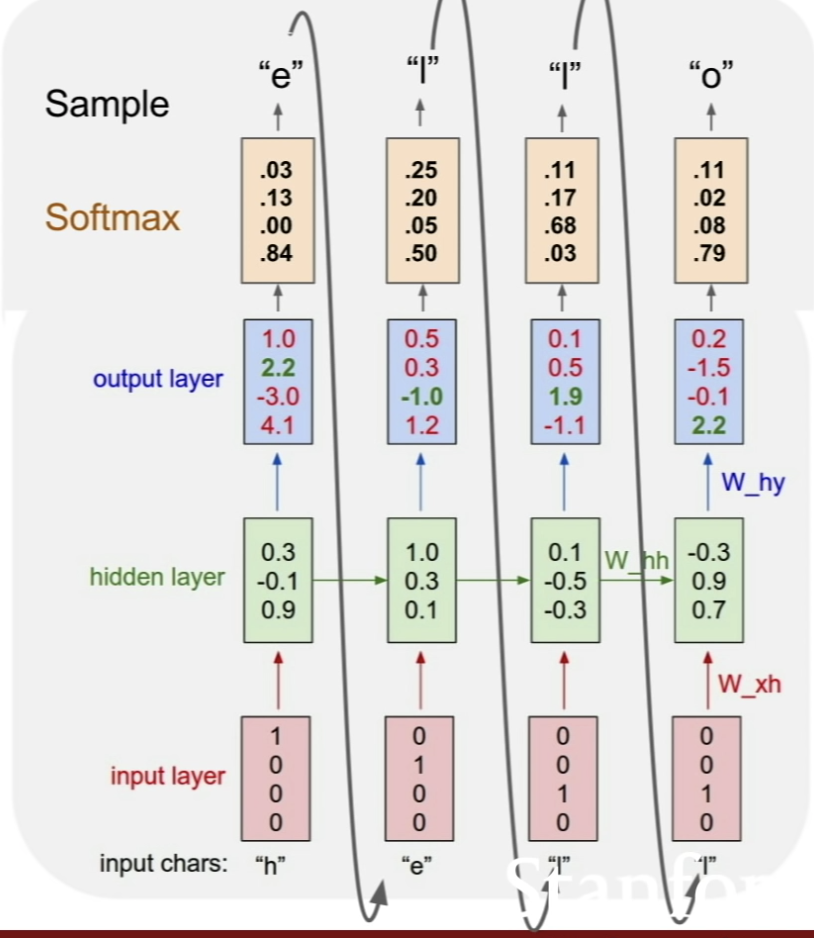
각각의 단어 벡터를 구하고, outside 벡터와 center 벡터를 dot product한 다음, softmax로 결정한다. 이것은 bag of words 모델로, 단어의 순서를 고려하지 않는 모델이다.
### Word2vec은 비슷한 단어들을 가까이 둠으로써 목적함수를 최대화할 수 있다.
# Optimization : Gradient Descent - 비용함수를 최소화해야 한다. - Gradient Descent는 기울기를 변형함으로써 비용함수를 최소화할 수 있다. - Update Equation
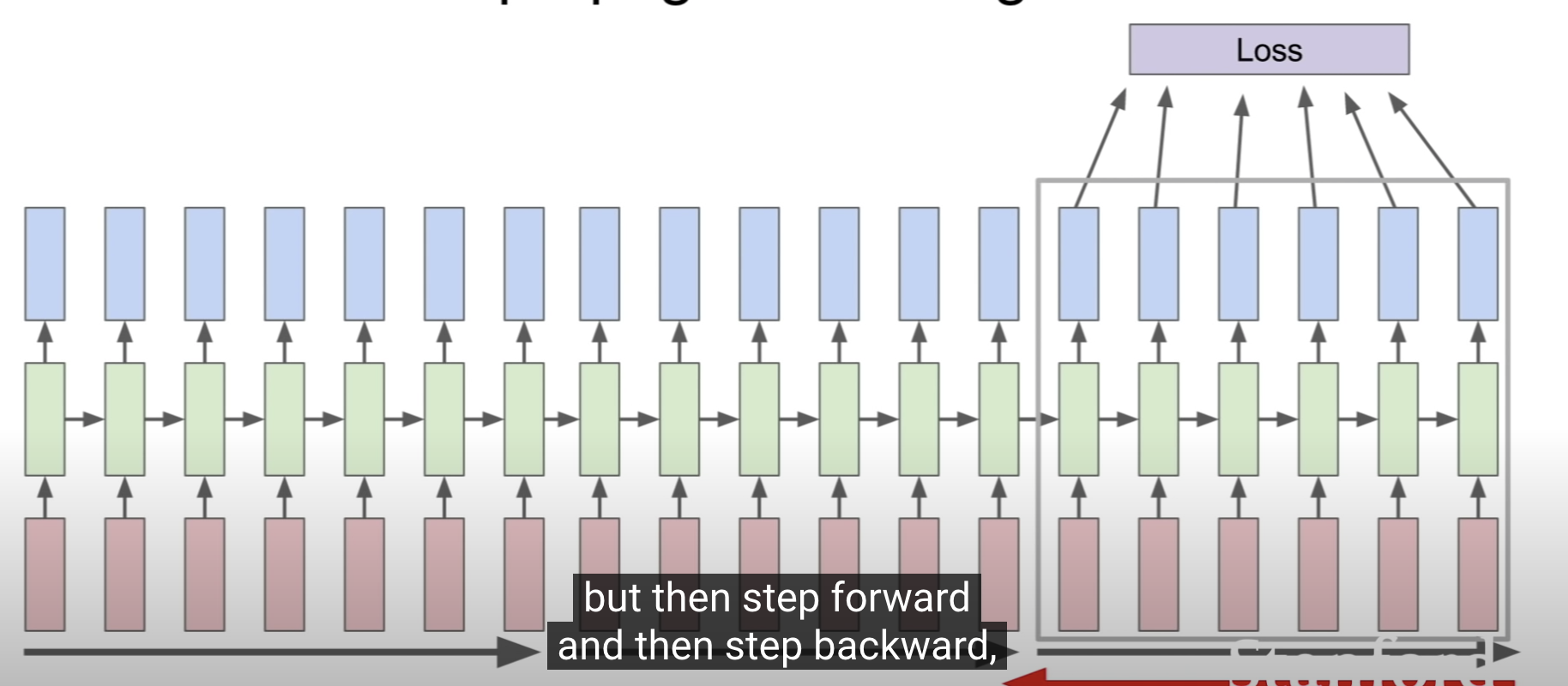
### 문제 : 모든 windows들에 함수를 적용하기 때문에 굉장히 비용이 크다. - 해결책 : Stochastic gradient descent -> 배치로 뽑아서 각각 업데이트하는 방식 - 일반적으로 row가 단어 하나의 벡터이다.
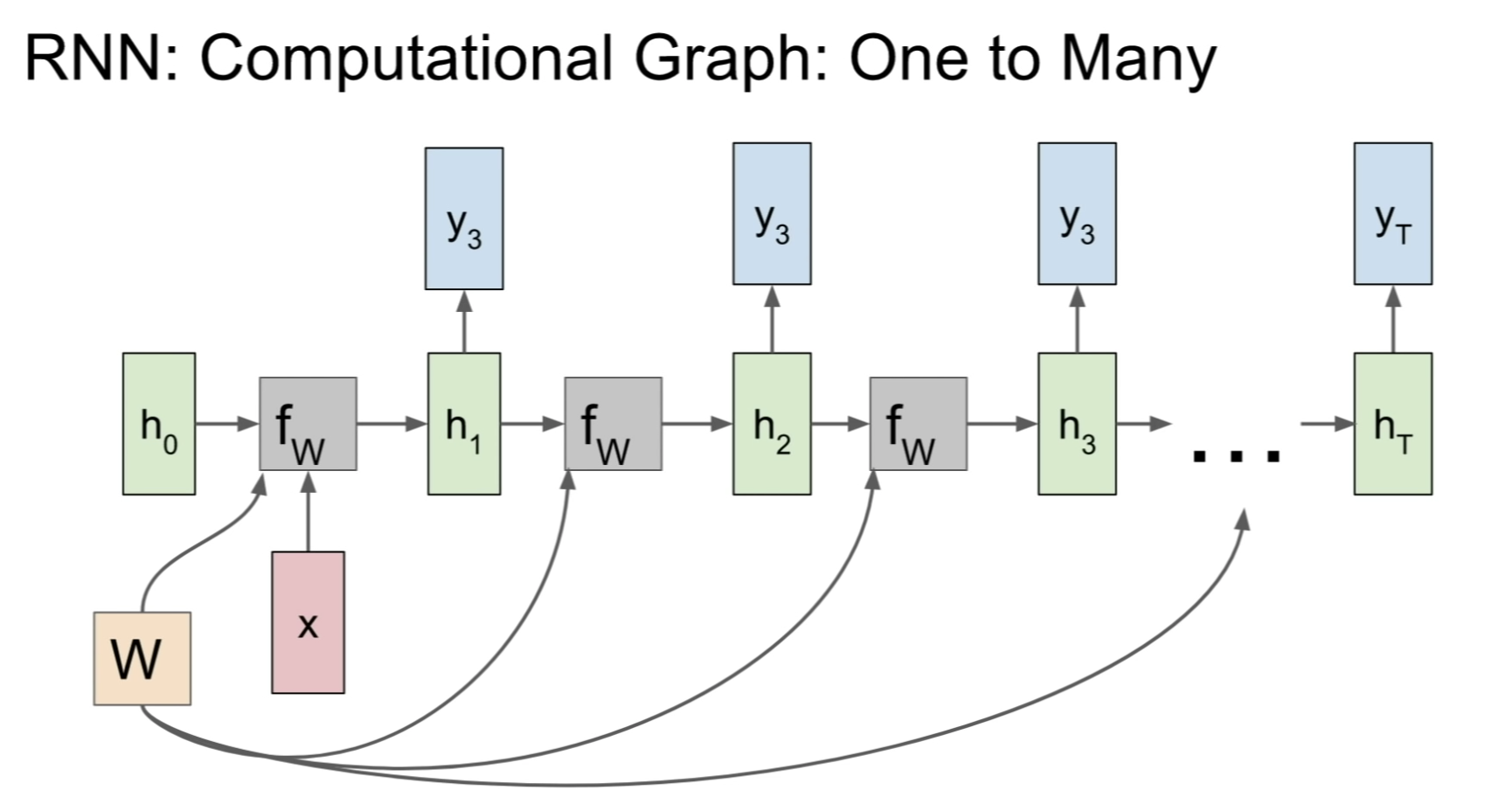
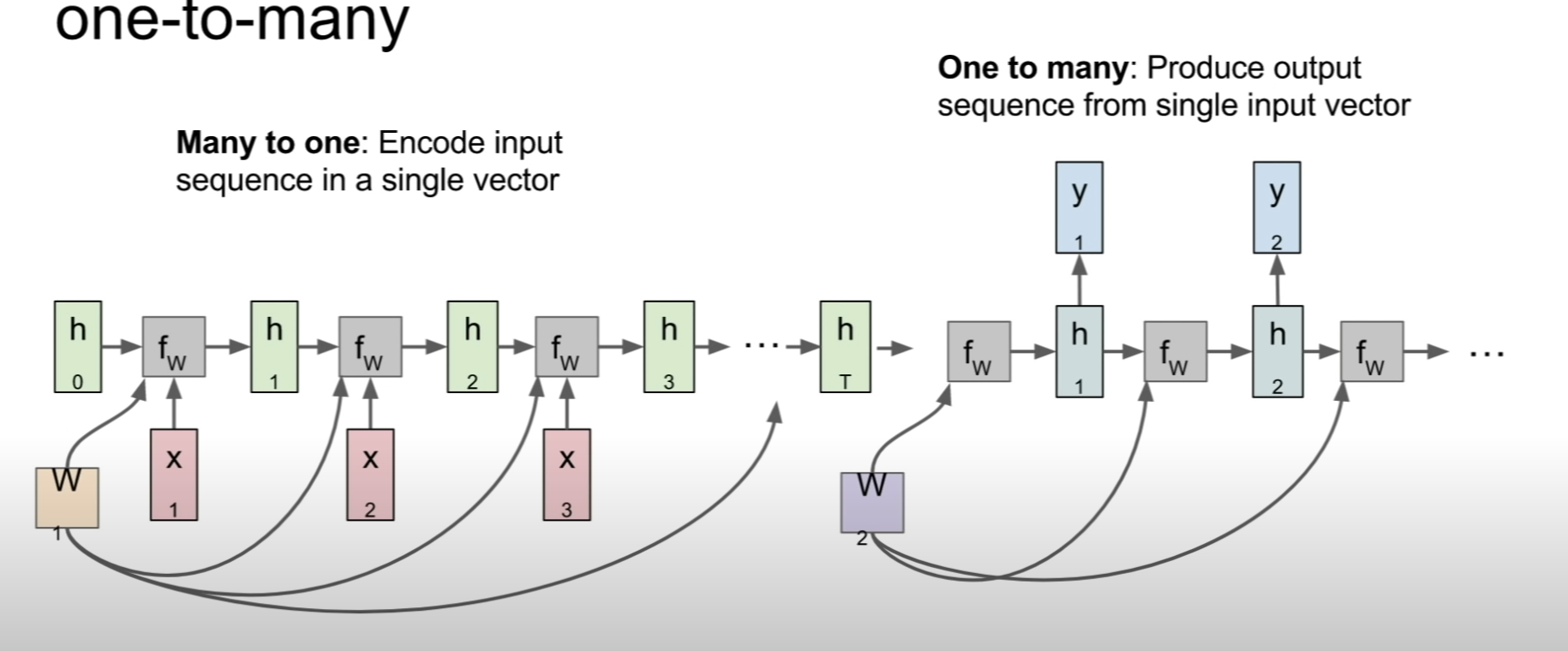
### Word2vec detail 두 가지 모델 방식 1) Skip-gram 2) Continuous Bag of words(CBOW)
Skip gram : center word가 주어지고, other words 예측 Cbow : other words가 주어지고, center word 예측
Skip gram model with Negative sampling Object function은 center와 others를 dot product : softmax -> logistic / sigmoid (0-1사이로 만듬) - 실제 outside words가 나타날 확률을 늘리고 - 랜덤 words가 center word 주위에 나타날 확률을 줄인다 - Unigram 분포에 따라 샘플링한다 -> 적게 나오는 단어가 더 자주 나오게 함 -> 왜?
차원 줄이기(hw1) - x = u * £ * vt - U와 v는 가로세로 동일 - U와 v 사이즈 안 맞는 부분은 무시
Vector 차이로 의미를 인코딩하기 : Co-occurence 확률의 비율이 곧 의미가 될 수 있다
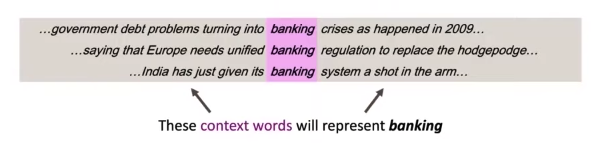
Word vector 구하기 - intrinsic : 단어 하나하나 평가, 빠르게 구함, vector간의 cosine distance로 유사도 구함, 만약 단어들간의 관계가 linear가 아니라면? - Extrinsic : 실제 태스크에서 평가, 시간이 많이 걸릴 수 있음
성능 semantic > syntactic Dimensional은 300 개 정도면 된다
동일 단어에 여러 뜻이 있는 경우에는 1)다른 벡터를 가지기도록 할 수 있음 2)linear algebraic하기 합쳐서 한 벡터로 표현할 수 있음