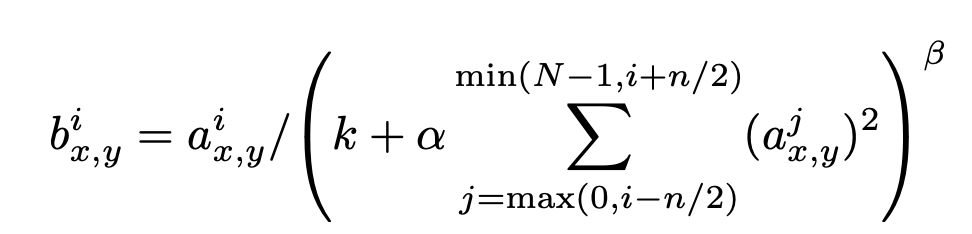논문 링크
https://arxiv.org/pdf/1311.2524.pdf
2014년 발행
0. TITLE
Rich feature hierarchies for accurate object detection and semantic segmentation
: 정확한 detection과 segmentation을 위한 feature 계층화
1. Abstract
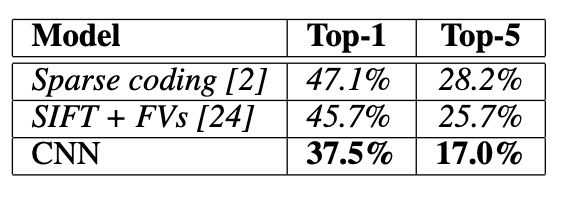
최근 Object Detection 성능이 정체되었다.
PASCAL VOC dataset에서 가장 높은 수준을 달성한 방식은 다수의 low-level image feature 들을 high-level context와 결합한 것이었다.
이 논문에서는 이전 최고 모델(VOC 2012에서 mAP 53.3%) 보다 mAP 기준 30% 향상시킨 알고리즘을 소개하려고 한다.
우리 알고리즘의 핵심 요소는
1) bottom-up region proposals에 높은 용량의 CNN을 적용할 수 있다는 것 (localize와 segment를 위해)
2) labeled 학습 데이터가 부족할 때, 보조 작업에 대한 supervised pre-training(domain-specific한 fine-tuning)이 엄청난 성능 향상을 가져다줌
-> (image classification) 의 충분한 데이터로 보조 작업을 하고 target task(detection)으로 fine-tune하는 방식
우리는 CNN과 함께 region proposals들을 결합하였기 때문에
우리의 알고리즘을 R-CNN(Regions with CNN features)라고 부르기로 하였다.
우리는 OverFeat라는 비슷한 CNN 구조를 가진 sliding window detector를 제안한 모델과 R-CNN을 비교하였다.
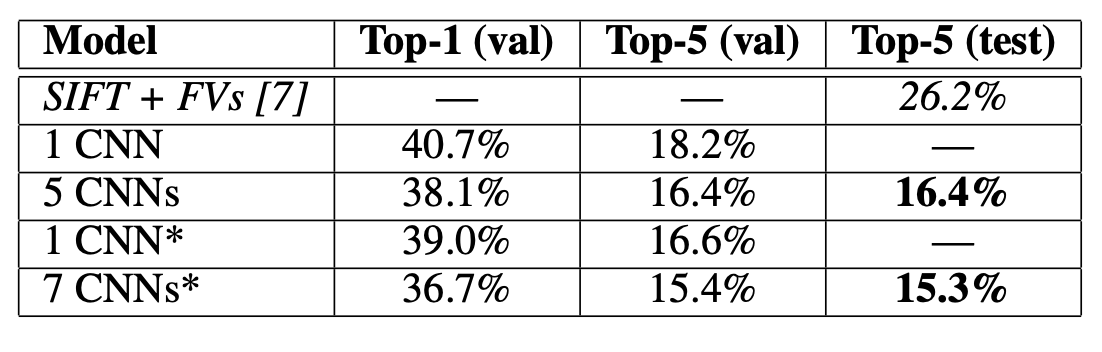
200-class ILSVRC2013 detection dataset에서 R-CNN이 OverFeat의 성능을 능가했다는 것을 증명하였다
2. Conclusion
우리 알고리즘의 두가지 인사이트
1) bottom-up region proposals에 높은 용량의 CNN을 적용할 수 있다는 것 (localize와 segment를 위해)
2) 데이터가 부족한 문제에 “supervised pre-training/domain-specific finetuning"이 굉장히 효과적이다.
3. Result & Discussion (Data 훑기)
1) Object detection with R-CNN
- Results on PASCAL VOC 2010-12
bounding box regression이 있는 것과 없는 결과로 두가지 제출하였다.
non-linear kernel SVM approach로 mAP 기준 35.1% -> 53.7%로 향상 + 더 빠름

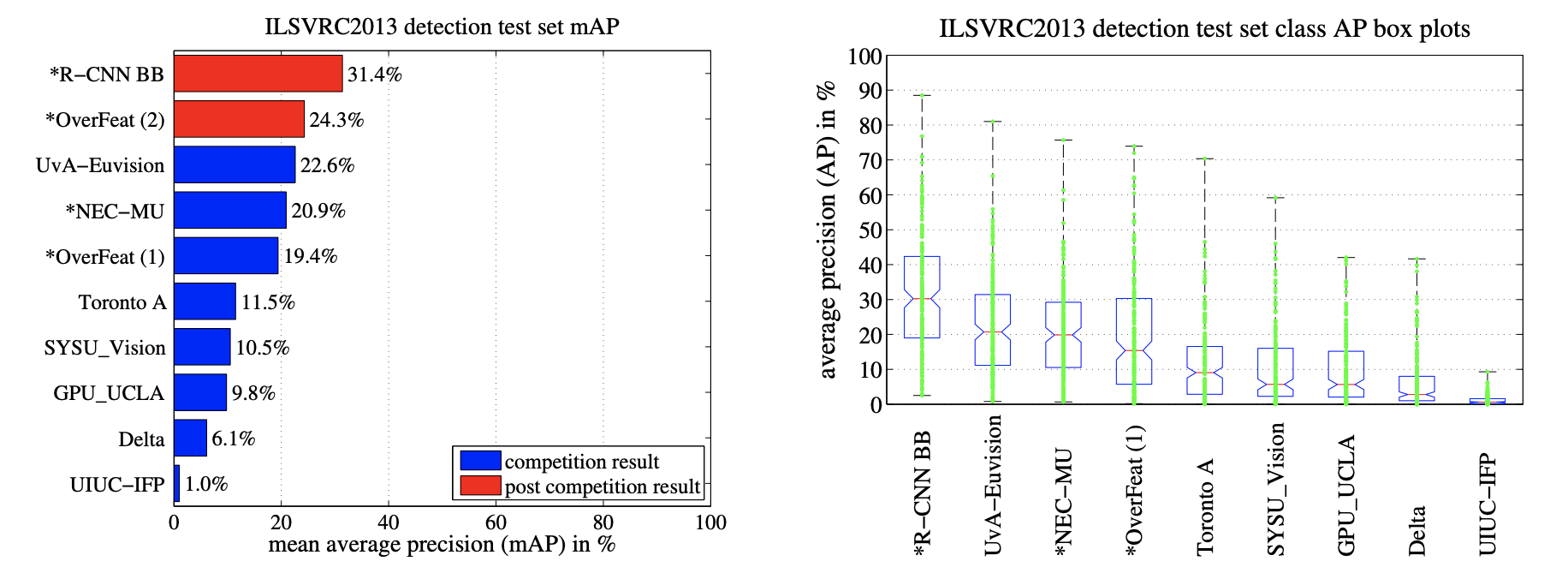
- Results on ILSVRC2013 detection
PASCAL VOC에서 사용한 하이퍼 파라미터와 동일하게 설정
bounding box regression이 있는 것과 없는 결과로 두가지 제출하였다.
2) Semantic segmentation
- Results on VOC 2011
[ validation results ]

fg strategy가 full strategy보다 약간 더 성능이 좋다.
이는 masked region shape가 더 강력한 signal을 보낸다는 것이다.
full+fg의 성능이 더 좋다.
즉, full features에 의해 제공받은 context가 유익하다는 것이다.
게다가 10시간 이상 걸렸던 O2P와 다르게, 20 SVR에 우리의 full-fg features를 적용한 것은 1시간에 안에 학습이 완료되었다.
[ test results ]

21개의 카테고리 중에 우리의 모델(full+fg R-CN fc6)이 11개의 카테고리에서 가장 높은 성능을 기록했다.
또한, overall 로서는 47.9로 가장 높은 수치를 기록하였다.
4. Introduction
이 논문은 CNN이 PASCAL VOC의 object detection task에서도 놀라운 성능을 보여줄 수 있다는 것을 첫번째로 보여줄 것이다.
두 가지에 집중하였다.
1) 깊은 신경망에서 localizing하는 것
2) 적은 object detection 데이터로도 높은 용량의 모델을 학습시키는 것
classification과는 다르게, object detection은 localizing object하는 것이 필요하다.
하지만, CNN은 굉장히 큰 receptive fields와 stride를 가지고 있기 때문에 sliding-window 방식을 적용하기에 어려움이 있다.
우리는 이를 "recognition using regions" 파라다임을 적용함으로써 해결하였다. -> object detection과 semantic segmentation에 모두 성공적이었다.
1) input image를 넣는다
2) 약 2000개의 bottom-up region proposals들을 추출한다 -> affine image warping을 적용하여 input size 통일
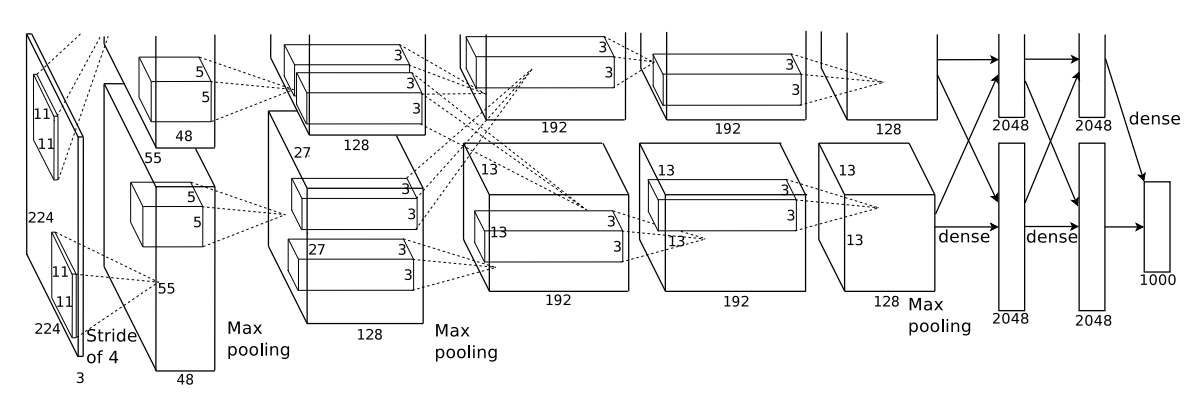
3) 각각의 proposal에 큰 CNN를 적용하여 고정 크기의 feature vector를 추출한다.
4) 각각의 region을 class-specific linear SVM을 적용하여 분류한다
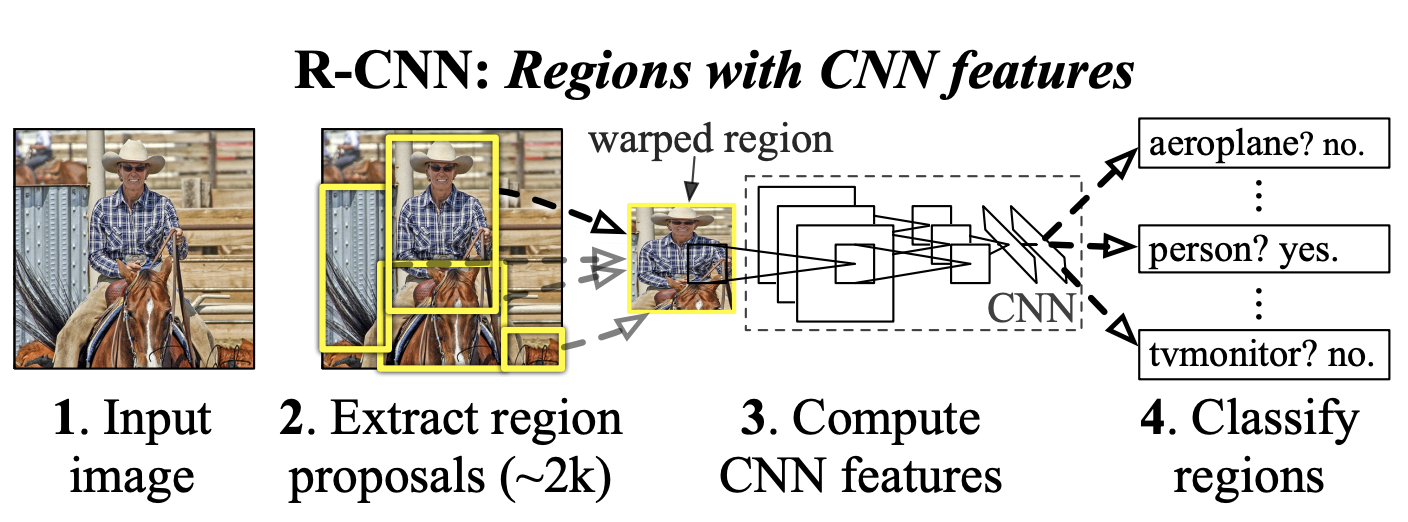
* affine image warping 기법을 이용하여, 각각의 region proposal로부터 고정 크기의 input image를 얻음
-> sliding-window 방식을 사용한 OverFeat model보다 성능이 높다. (mAP 기준)
두 번째 문제는, 큰 CNN을 적용하기에 레이블된 데이터가 부족하다는 것이었다.
기존의 전통적인 해결방식은 unsupervised pre-training과 supervised fine-tuning을 사용하는 것이었는데,
우리는 1) 대규모의 보조 데이터셋에(ILSVRC) supervised pre-training을 적용하고
2) 작은 데이터셋(PASCAL)에 domain-specific한 fine-tuning을 적용하는 방식을 이용하였다.
이는, 데이터가 적을 때 높은 용량의 CNN을 학습시키는 데에 효과적이었다.
우리의 실험에서 detection을 위한 fine-tuning을 통해 mAP를 8%point나 올릴 수 있었다.
'AI > 논문리뷰' 카테고리의 다른 글
| [Segmentation] Deep High-Resolution Representation Learning 논문 리뷰 (0) | 2022.05.17 |
|---|---|
| [Segmentation] Attention 논문 리뷰 (0) | 2022.05.16 |
| [Segmentation] 계층적 multi-scale HRNet-OCR attention 논문 리뷰 (0) | 2022.05.12 |
| [Segmentation] FCN 논문 리뷰 (0) | 2022.05.10 |
| [Classification] AlexNet 논문리뷰 (0) | 2022.05.02 |