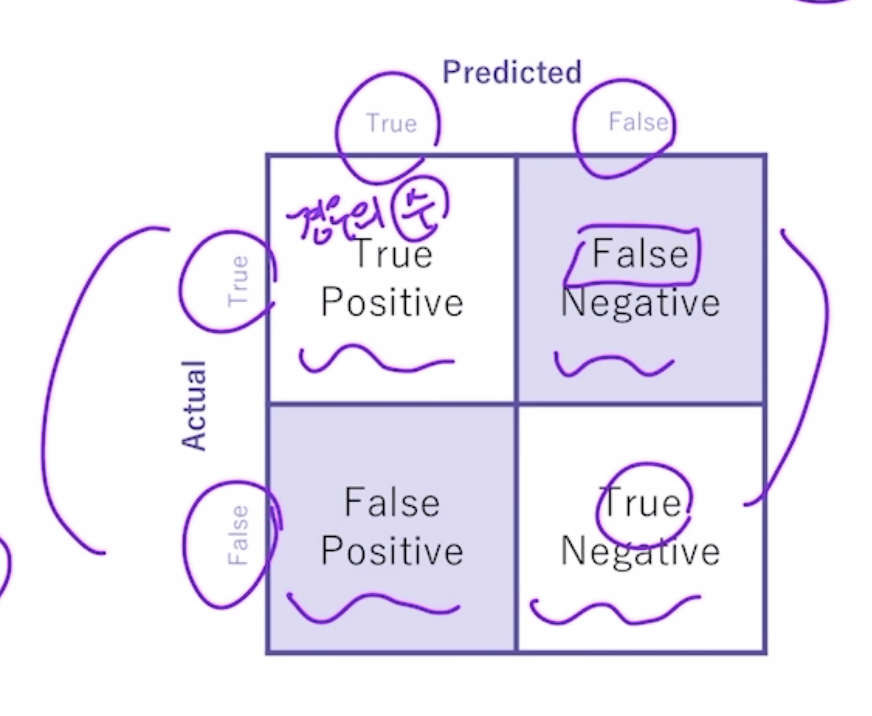
오차 행렬
불균형한 레이블 데이터 세트에서 예측할 때 발생할 수 있는 한계점을 극복하기 위한 방법 중 하나
위 네개의 값을 조합해 Classifier의 성능을 측정할 수 있는 주요 지표인 정확도(Accuracy), 정밀도(Precision), 재현율(Recall) 값을 알 수 있다.
- 정확도 = 예측 결과와 실제 값이 동일한 건수 / 전체 데이터 수 (TN + TP) / (TN + FP + FN + TP)
- 정밀도 = 예측을 P로 한 대상중에 예측과 실제값이 P로 일치한 데이터의 비율 TP / (FP + TP)
- 재현율 = 실제 값이 P인 대상 중에 예측과 실제 값이 P로 일치한 데이터의 비율 TP / (FN + TP)
분류하려는 업무의 특성상 정밀도 또는 재현율이 특별히 강조돼야 할 경우, 분류의 결정 임곗값을 조정해 정밀도 또는 재현율의 수치를 높일 수 있다.
그러나 둘은 상호 보완적인 지표기 때문에 어느 한쪽을 강제로 높이면 다른 하나의 수치는 떨어지기 쉽다.
일반적으로 이진 분류에서는 예측의 임곗값을 50%로 정한다.
그러나 임계값을 떨어트리면 정밀도는 떨어지고 재현율이 올라간다.
아래는 임곗값 변화에 따른 평가 지표이다.
F1 스코어
정밀도와 재현율을 결합한 지표
recall = 재현율
precision = 정밀도
ROC 곡선과 AUC
ROC 곡선 (Receiver Operation Characteristic Curve)은 FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate, 재현율/민감도)이 어떻게 변하는지를 나타내는 곡선
TNR = TN / (FP + TN)
FPR = FP / (FP + TN) = 1 - TNR = 1 - 특이성
ROC 곡선이 가운데 직선에 가까워질수록 성능이 떨어지는 것
분류 결정 임곗값을 이용하여 FPR을 0부터 1까지 변경하며 TPR의 변화 값을 구함으로써 ROC 곡선을 구할 수 있다.
ex) FPR을 0으로 만들려면 임곗값을 1로 지정
roc_curve() API 이용
'AI > Machine Learning' 카테고리의 다른 글
| [Tave 7기 캐글스터디] AdaBoost, XGBoost, LGBM (0) | 2021.04.07 |
|---|---|
| [Tave 7기 캐글스터디] 결정 트리 & 랜덤포레스트 (0) | 2021.04.07 |
| 2장 분류 (0) | 2021.02.18 |
| 정규화 / 회귀 알고리즘 평가 지표 (0) | 2021.02.03 |
| 과적합(Overfitting) 방지방법 (0) | 2021.02.02 |